Token-saving updates on the Anthropic API

We've made several updates to the Anthropic API that let developers significantly increase throughput and reduce token usage with Claude 3.7 Sonnet. These include: cache-aware rate limits, simpler prompt caching, and token-efficient tool use.
Together, these updates will help you process more requests within your existing rate limits and reduce costs with minimal code changes.
Increase your throughput with prompt caching
Prompt caching allows developers to store and reuse frequently accessed context between API calls. This lets Claude maintain knowledge of large documents, instructions, or examples without sending the same information with each request—reducing costs by up to 90% and latency by up to 85% for long prompts. We’ve released two improvements to prompt caching for Claude 3.7 Sonnet that work together to help you scale more efficiently.
Cache-aware rate limits
Prompt cache read tokens no longer count against your Input Tokens Per Minute (ITPM) limit for Claude 3.7 Sonnet on the Anthropic API. This means you can now optimize your prompt caching usage to increase throughput and get more out of your existing ITPM rate limits. Your Output Tokens Per Minute (OTPM) rate limit remains the same.
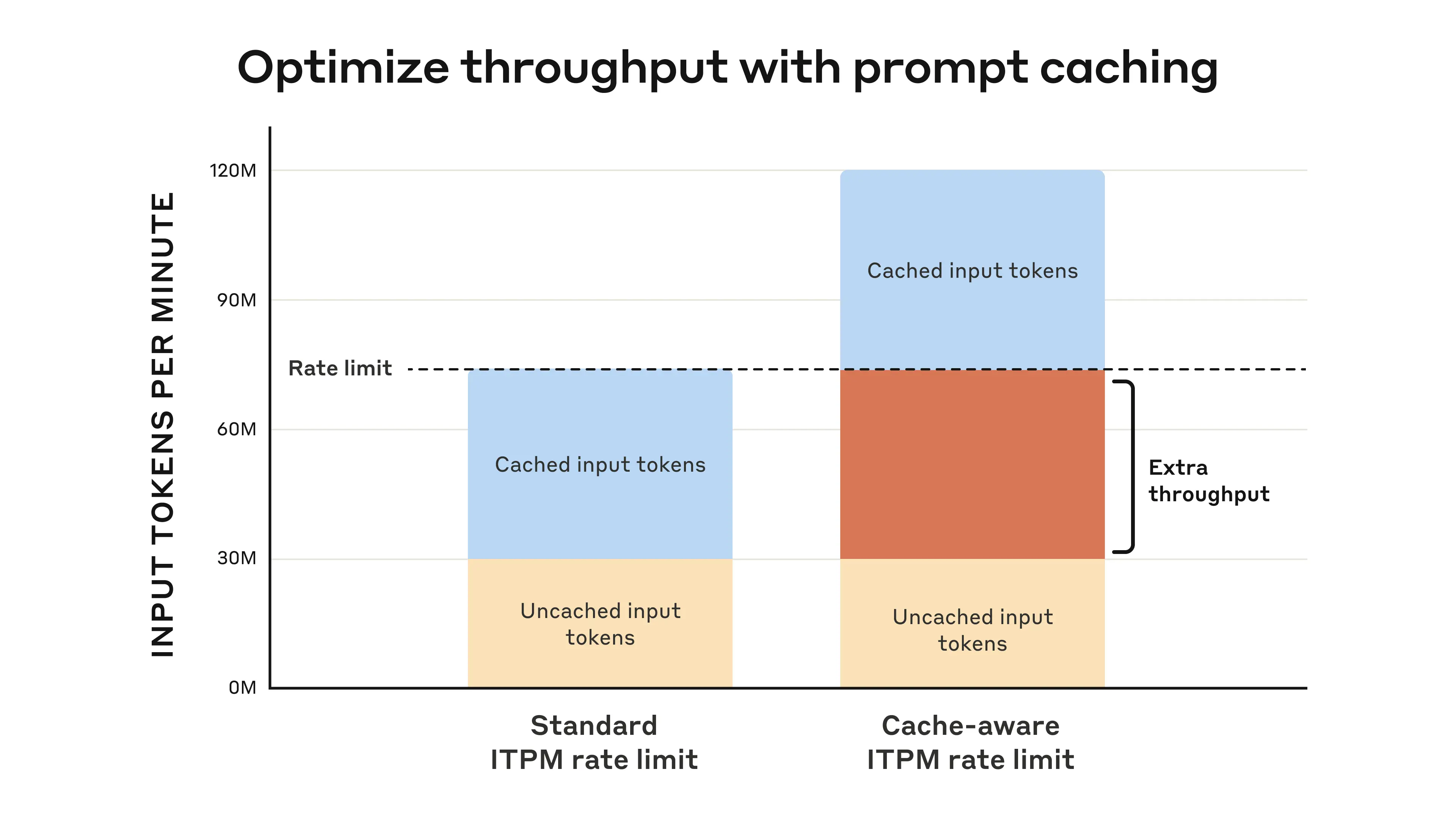
This makes Claude 3.7 Sonnet particularly powerful for applications that benefit from extensive context while requiring high throughput, such as:
- Document analysis platforms that need to maintain large knowledge bases in context
- Coding assistants that reference extensive codebases
- Customer support systems that leverage detailed product documentation
Cache-aware ITPM limits are available for Claude 3.7 Sonnet on the Anthropic API.
Simpler cache management
We've updated prompt caching to be easier to use. Now, when you set a cache breakpoint, Claude automatically reads from your longest previously cached prefix.
You no longer need to manually track and specify which cached segments to use as we automatically identify and use the most relevant cached content. This not only reduces your workload, but also frees up more tokens.

This feature is available on the Anthropic API and Google Cloud’s Vertex AI. Explore our documentation to learn more.
Token-efficient tool use
Claude is already capable of interacting with external client-side tools and functions. This update lets you equip Claude with your own custom tools to perform tasks—like extracting structured data from unstructured text or automating simple tasks via APIs. Claude 3.7 Sonnet now supports calling tools in a token-efficient manner, reducing output token consumption by up to 70%. On average, early users have seen a reduction of 14%.
To use this feature, simply add the beta header token-efficient-tools-2025-02-19 to a tool use request with Claude 3.7 Sonnet. If you are using the SDK, ensure that you are using the beta SDK with anthropic.beta.messages.
Token-efficient tool use is currently available in beta on the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI.
Text_editor tool
We also introduced a new text_editor tool, designed for applications where users collaborate with Claude on documents. With the new tool, Claude can make targeted edits to specific portions of text within source code, documents, or research reports. This reduces token consumption and latency, all while increasing accuracy.
Developers can easily implement this tool in their applications by providing it in their API requests and handling the tool use responses.
The text_editor tool is available on the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. See our documentation to get started.
Customer Spotlight: Cognition
Early users, like Cognition, are leveraging these updates to improve token efficiency and response quality. Cognition is an applied AI lab and the maker of Devin, a collaborative AI teammate that helps ambitious engineering teams achieve more.
“Prompt caching allows us to provide more context about the codebase to get higher quality results while reducing cost and latency. With cache-aware ITPM limits, we are further optimizing our prompt caching usage to increase our throughput and get more out of our existing rate limits,” said Scott Wu, Co-founder and CEO at Cognition.
Get started now
These features are available today to all Anthropic API customers. You can implement them immediately with minimal code changes:
- Take advantage of cache-aware rate limits: Use prompt caching with Claude 3.7 Sonnet.
- Implement token-efficient tool use: Add the beta header token-efficient-tools-2025-02-19 to your requests and start saving tokens.
- Try the text_editor tool: Integrate it into your applications for more efficient document editing workflows.