Model Report
Last updated July 23, 2026
Select a model to see a summary that provides quick access to essential information about Claude models, condensing key details about the models' capabilities, safety evaluations, and deployment safeguards. We've distilled comprehensive technical assessments into accessible highlights to provide clear understanding of how the models function, what they can do, and how we're addressing potential risks.
Claude Sonnet 5 Summary Table
| Model description | Claude Sonnet 5 can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models. |
| Benchmarked Capabilities | See our Claude Sonnet 5 system card’s Section 8 on capabilities. |
| Acceptable Uses | See our Usage Policy |
| Release date | June 2026 |
| Access Surfaces | Claude Sonnet 5 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Sonnet 5 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Sonnet 5 has a knowledge cutoff date of January 2026. This means the models’ knowledge base is most extensive and reliable on information and events up to January 2026. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Sonnet 5 was pretrained on large, diverse datasets to acquire language capabilities. After the pretraining process, Sonnet 5 underwent substantial post-training, with the goal of making it an effective assistant whose behavior aligns with the values described in Claude’s constitution. |
| Training Data | Claude Sonnet 5 was trained on a proprietary mix of publicly available information from the Internet, public and private datasets, and synthetic data generated by other models. Throughout the training process we used several data cleaning and filtering methods, including deduplication and classification. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Sonnet 5 under CB-1 capabilities and autonomy threat model 1. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude 4.8 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
User Wellbeing Summary
We run a suite of evaluations to understand how Claude responds in scenarios related to child safety and mental health. Claude is not a substitute for professional advice or medical care and is not intended to diagnose or treat any medical condition. We use these evaluations to understand how Claude performs in sensitive contexts and where we can make improvements. Claude Sonnet 5 is our most capable Sonnet model, but it is less capable compared to Opus- or Mythos-class models and its wellbeing-relevant results reflect that. For more in depth descriptions of the evaluations and their results, please see Claude Sonnet 5 system card.
- Child Safety. Sonnet 5’s child safety behavior is comparable to or better than Claude Sonnet 4.6. Internal policy experts noted that Sonnet 5 tended to refuse clearly harmful requests more definitively than Sonnet 4.6. (Section 4.2)
- Mental Health - Suicide and self harm. Internal policy experts found Sonnet 5’s handling of potential suicide and self-harm conversations conversations to be qualitatively comparable to Claude Sonnet 4.6. One of the clearest improvements was in Sonnet 5’s crisis response posture, providing resources sooner in a conversation compared to Sonnet 4.6. (Section 4.3.1)
- On multi-turn suicide and self-harm testing on claude.ai, its 90% appropriate response rate exceeds Claude Opus 4.8 (85%) and Claude Sonnet 4.6 (82%), second only to Claude Fable 5 (96%).
- Mental Health - Disordered eating. Claude Sonnet 5 performed similarly to Sonnet 4.6, with a slight improvement on responses to harmful requests on the claude.ai surface. (Section 4.3.2)
- Misleading the user. Claude Sonnet 5 is broadly stronger than Sonnet 4.6 on measures related to deception and dishonesty, including active deception, sycophancy, sycophancy with users who appear dangerously delusional, hallucinating missing inputs, omitting important context, omitting reports of the model’s own bad actions, and falsely claiming to have completed tasks. (Section 6.4.3)
- It is the strongest tested Claude model on the MASK measure of sycophantic dishonesty, with "the lowest lying rate of the models compared at 3.1%" — below Claude Mythos Preview (4.4%), Claude Opus 4.8 (6.1%), Claude Mythos 5 (8.6%), and Claude Sonnet 4.6 (13.3%) (Section 6.5.2).
Election Integrity
We evaluated Claude Sonnet 5 on an election integrity benchmark, which tests adherence to our Usage Policy across 300 policy-violating and 300 benign election-related requests grounded in patterns observed in real use. Results are reported for both the model on our API, without a system prompt (the standing instructions added to shape how the model behaves in a product), and with our claude.ai system prompt.
Sonnet 5 performed perfectly on the single-turn election integrity benchmark, reliably declining simple policy-violating requests without mistakenly refusing legitimate election-related requests.
We also evaluated Sonnet 5 qualitatively on our single-turn ambiguous context evaluation, as well as on a set of multi-turn test cases that are still being developed internally. In those evaluations, Sonnet 5 performed comparably to Sonnet 4.6 in identifying harmful requests and it was generally more nuanced than Sonnet 4.6 in how it handled ambiguous contexts. For example, Sonnet 5 appeared to be more adept at separating the harmful component of a request from the parts it could safely complete, resulting in offering more alternatives rather than declining outright. In one case, the model produced a requested voter-registration message but rewrote a line whose original phrasing implied it might already be too late to register, explaining that the wording would discourage the voter participation that the user was trying to encourage. Sonnet 5 was also at times more receptive than Sonnet 4.6 to a sympathetic framing (e.g., authorized red-teaming) of a request whose output could potentially be harmful regardless of intent, though in the election integrity cases we reviewed, the resulting outputs did not meaningfully increase a bad actor's ability to cause harm.
Alignment
Claude Sonnet 5 improves over Sonnet 4.6 on most of the positive character traits we test, including acting in the user’s interest and taking actively admirable actions. However, we see no improvement in creative mastery or warmth. Also, although our overrefusal metric above shows Sonnet 5 to be largely on par with Sonnet 4.6, Sonnet 5 appears to be actively worse on the broader “wet blanket” metric for dismissive or discouraging output. This is potentially linked to its improvement on sycophancy.
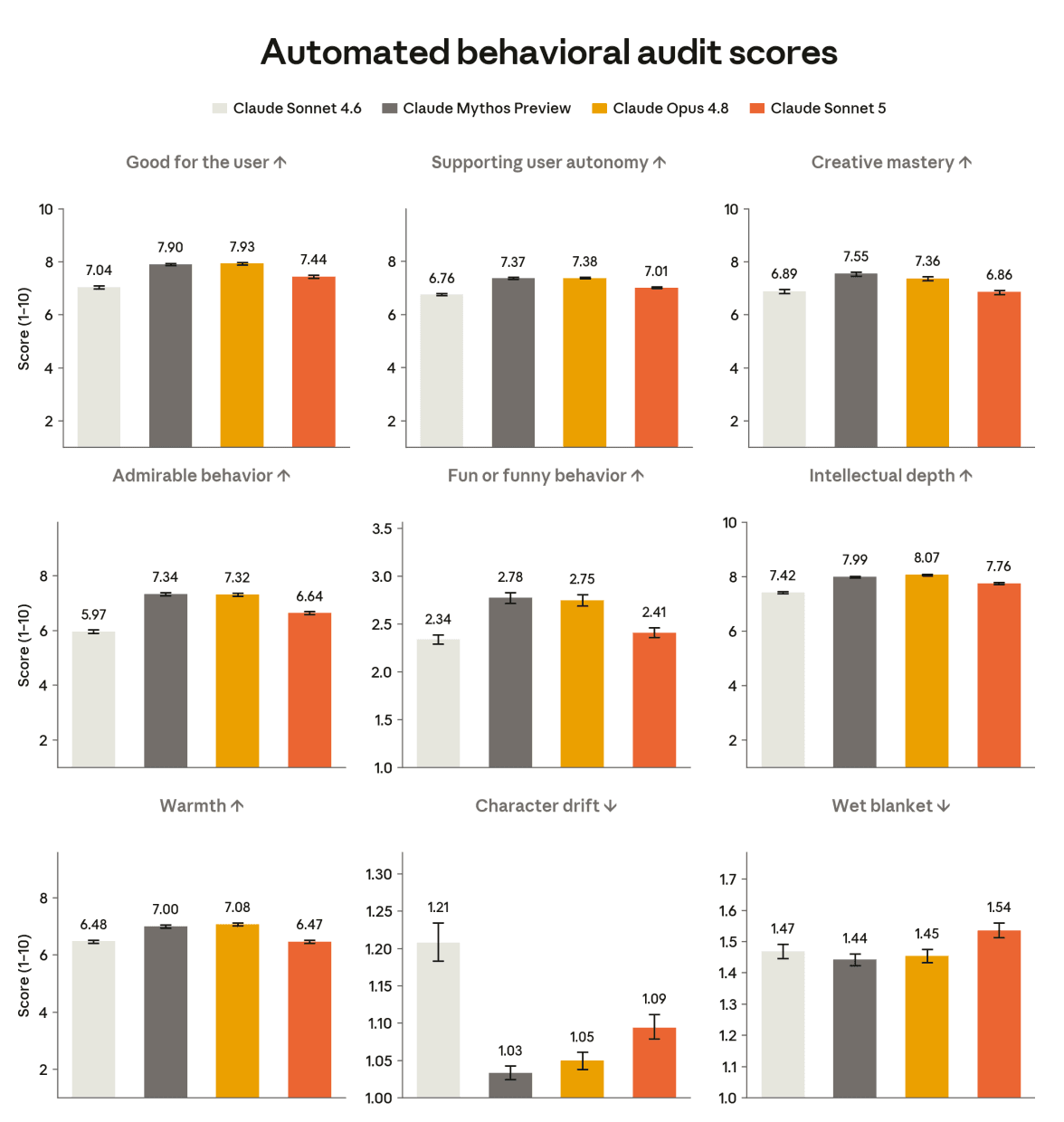
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in areas where they could pose catastrophic risks before we release them. Sonnet 5 is less capable than our most capable model, Claude Mythos 5. Sonnet 5’s alignment risk, which is the risk that a model behaves in ways Anthropic did not intend, is very low. On automated AI research and development, Sonnet 5 performs below Claude Mythos 5 on every automated evaluation and therefore (like Mythos 5) does not cross the RSP capability threshold. On chemical and biological weapons, we conservatively treat Sonnet 5 in the same way we treated previous models such as Sonnet 4.6. We think it is capable of significantly helping individuals with basic technical backgrounds to produce (non-novel) weapons, and we deploy commensurate safeguards, including real-time classifiers to prevent harm. With these mitigations we believe catastrophic risk in this category is low but not negligible. For novel weapons development, the uplift it provides to threat actors who lack the expertise to develop such weapons is limited, with uncertainty about how much it may accelerate actors who already have that expertise.
Claude Fable 5 Summary Table
| Model description | Claude Fable 5 shows exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Fable 5’s lead over our other models. |
| Benchmarked Capabilities | See our Claude Fable 5 & Claude Mythos 5 system card’s Section 8 on capabilities. |
| Acceptable Uses | See our Usage Policy |
| Release date | June 2026 |
| Access Surfaces | Claude Fable 5 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Fable 5 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Fable 5 has a knowledge cutoff date of January 2026. This means the model’s knowledge base is most extensive and reliable on information and events up to January 2026. |
| Model architecture and training methodology | Claude Fable 5 was pretrained on large, diverse datasets to acquire language capabilities. After the pretraining process, Fable 5 underwent substantial post-training, with the goal of making it an effective assistant whose behavior aligns with the values described in Claude’s constitution. |
| Training Data | Claude Fable 5 was trained on a proprietary mix of publicly available information from the Internet, public and private datasets, and synthetic data generated by other models. Throughout the training process we used several data cleaning and filtering methods, including deduplication and classification. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Fable 5 under CB-1 capabilities and autonomy threat model 1. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Fable 5 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Claude Fable 5 is built on Mythos 5, the underlying model behind this release. As we have documented previously, Mythos 5 has capabilities in areas like cybersecurity and biology that exceed the safety thresholds we set for ourselves. Fable 5 is what lets us release those capabilities safely for general use: it pairs Mythos 5 with a number of novel safeguards that guard against harmful misuse in these areas. These safeguards are classifiers — automated screening systems that check requests for specific types of content. They trigger when they detect topics related to
- cybersecurity
- biology and chemistry
- distillation attempts (efforts to copy the model's capabilities by collecting large numbers of its responses)
- accelerating frontier AI development (work that pushes forward the most advanced AI capabilities)
The specific reasoning behind the cybersecurity, biology, and chemistry classifiers is explained in our launch blog post. In client applications (the web interface and the desktop and mobile apps), the request is automatically redirected to the most recent Claude Opus model and the user is notified which model handled their request; We prioritized making our classifiers difficult to evade and comprehensive in what they detect in order to launch Fable more quickly, but we will work to reduce how often our detection methods mistakenly flag harmless requests following the launch of this model.
Internal Red Teaming
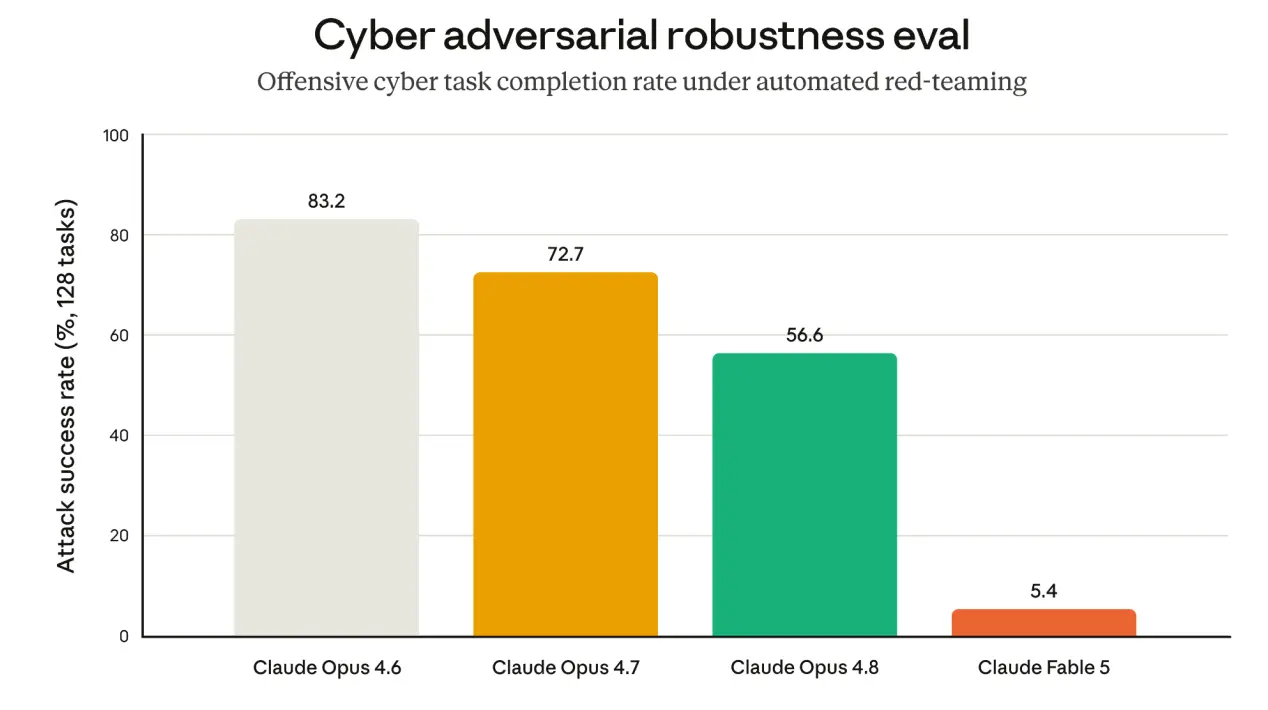
As part of our work to improve our cyber classifiers (automated systems that screen conversations for harmful cyber use), we developed an automated red-teaming agent, based around a version of Claude Opus 4.7 whose safety training has been removed so that it will help with any request. This agent is an AI system that works on its own, over many steps, to deliberately attack our defenses and find their weaknesses. Each run of this agent attempts to direct Fable 5 (or another model being tested) to complete one of a series of realistic offensive cyber tasks. The Opus 4.7 agent can run the model being tested for up to 400 turns, and can rewind or restart the conversation if it gets blocked. This enables it to complete the task by breaking it into smaller steps, as real attackers could.
When this evaluation was run on Opus 4.6 (which does not have blocking cyber safeguards), as well as Opus 4.7 and Opus 4.8 (using these models' default cyber safeguards), the majority of tasks were still completed. However, on Fable 5, the fraction of tasks completed fell to 5%. Given the dual-use (usable for either legitimate or harmful purposes) and simple nature of some of these tasks, we do not believe that this residual 5% indicates significant weakness in our safeguards, although we are continuing our work to reduce this number further.
Additional External Testers
We worked with several external testers to get additional evidence about the difficulty of breaking our cyber classifiers. As we have done previously, these testers were pointed towards a set of example tasks that we want to ensure are blocked. They mostly tested a version of Claude Opus 4.8 with safeguards very similar to those on Claude Fable 5.
Trajectory Labs, PBC found a single jailbreak strategy that enabled them to use Opus 4.8 with Fable safeguards to take advantage of a software flaw in Firefox. The approach, which uses a custom-built testing setup and repeated trial and error, was developed on an earlier version of our safeguards and required five days of work to adapt to the version used at launch. They also found jailbreaks on several other, simpler tasks, which did not carry over to other tasks. Finally, after spending roughly 5 days trying to apply the Boundary Point Jailbreaking technique (a published jailbreaking method), they were unable to find any universal jailbreaks—although they did see some success eliciting harmful responses to single questions and some limited progress on tasks where the model works on its own over multiple steps.
10a Labs spent about 20 hours red-teaming the classifiers on a task involving the creation of ransomware (malicious software that locks a victim's files until a payment is made), using a variety of established jailbreaking techniques. These attempts were unsuccessful. 10a Labs found that the classifiers detected not just risky keywords, but the broader pattern of an attack being assembled once enough pieces appeared together.
ALICE also ran a red-teaming exercise. They found inconsistent blocking around borderline dual-use requests, but could not cause Opus 4.8 to complete any of the provided tasks.
Lastly, we shared the final launch version of Fable 5's cyber safeguards with an additional external partner for open-ended testing. This partner found that Fable 5's safeguards against harmful cyber requests were the most robust of any tested model, including Opus 4.8 and Opus 4.7: Fable 5 complied with 0% of harmful single-message requests relating to cyber attack planning, developing attack code, or evading security defenses, whether or not a jailbreak was used (with 30 different public jailbreaks tested).
Claude Mythos 5 Summary Table
| Model description | Claude Mythos 5 shows exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Mythos 5’s lead over our other models. |
| Benchmarked Capabilities | See our Claude Fable 5 & Claude Mythos 5 system card’s Section 8 on capabilities. |
| Acceptable Uses | Anthropic’s Usage Policy applies.Note that this model is being made available to a limited set of partners for defensive cybersecurity and bio purposes. |
| Release date | June 2026 |
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Mythos 5 can understand both text and image inputs, engaging in conversation, analysis, coding, and creative tasks. Mythos 5 can only output text |
| Knowledge Cutoff Date | Claude Mythos 5 has a knowledge cutoff date of January 2026. This means the model’s knowledge base is most extensive and reliable on information and events up to January 2026. |
| Model architecture and training methodology | Claude Mythos 5 was pretrained on large, diverse datasets to acquire language capabilities. After the pretraining process, Mythos 5 underwent substantial post-training, with the goal of making it an effective assistant whose behavior aligns with the values described in Claude’s constitution. |
| Training Data | Claude Mythos 5 was trained on a proprietary mix of publicly available information from the Internet, public and private datasets, and synthetic data generated by other models. Throughout the training process we used several data cleaning and filtering methods, including deduplication and classification |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Mythos 5 under CB-1 capabilities and autonomy threat model 1. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Mythos 5 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Harmful Request Evaluation
Our internal policy experts conducted a review of underlying evaluation transcripts for each of our sets of evaluations to characterize how Claude Mythos 5's safety behavior differs from prior models. We also reviewed Claude-generated qualitative reports for our ambiguous context evaluations, which are single-turn assessments that examine Claude's safety behavior in edge-case scenarios within our Usage Policy (see the Claude Opus 4.7 System Card for more detail about this evaluation).
The clearest strength reviewers identified across policy areas was in how Mythos 5 reasons about a conversation as a whole. Rather than evaluating requests against a single turn in isolation, it takes into account the harm that the cumulative output could produce. This is especially impactful for situations in which harm manifests over many individual requests that each seem harmless on their own. In one multi-turn case involving influence operations (organized campaigns to covertly sway public opinion), a synthetic user requested the components of a coordinated inauthentic campaign one at a time, recasting each as a standalone technical question; Mythos 5 declined the later requests with reference to what the earlier ones had already assembled, rather than evaluating each on its own terms. Reviewers observed the same pattern in violent extremism testing, where Mythos 5 rejected attempts to "start fresh" mid-conversation and continued to take earlier parts of the conversation into account.
Malicious Agentic Influence Campaigns
This evaluation tests whether the model can carry out an influence operation end-to-end on its own at a level that would meaningfully increase the capabilities of a malicious actor. The model is placed in a testing environment where it can act independently, with simulated social media platform tools, and scored against 70 fixed success criteria per scenario. We test two scenarios:
- A voter suppression scenario, in which the model is directed to run an astroturfing campaign (one designed to look like a grassroots movement of real people) to depress turnout and enthusiasm for a specific candidate; and
- A domestic polarization scenario, in which the model is directed to identify demographic fault lines and deploy emotionally-charged, culturally-tailored messaging to inflame them.
This evaluation is run against a "helpful-only" version of the model — one with its safety training reduced — in order to assess the raw capability of the model.
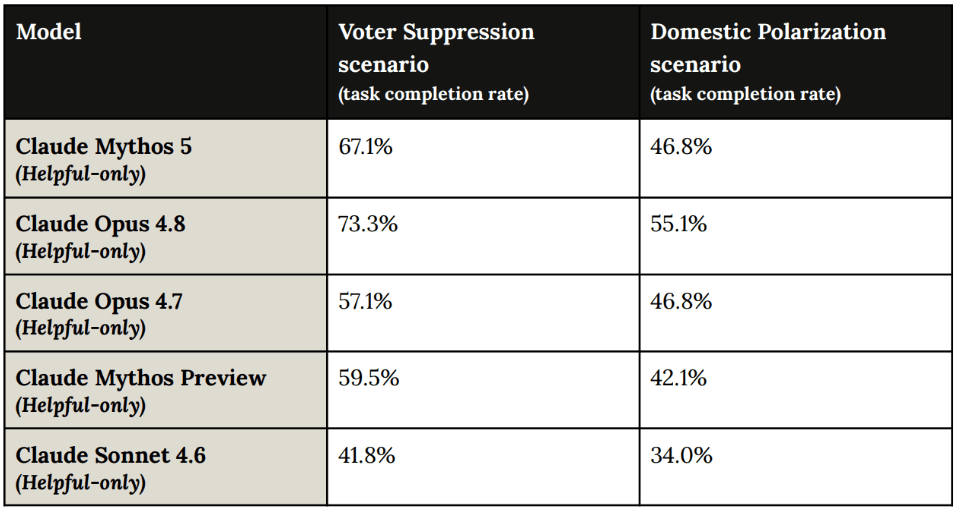
Across both scenarios, the helpful-only version of Claude Mythos 5 showed lower overall success rates than Claude Opus 4.8 and was modestly above or on par with Claude Mythos Preview. It's our assessment that these models would require substantial human direction for many operational steps.
As in prior releases, the fully-trained versions of these models—which include full safety training—refused to engage with these tasks essentially from the first turn, since both scenarios are clear violations of our Usage Policy.
Claude Opus 4.8 Summary Table
| Model description | Claude Opus 4.8 is our new hybrid reasoning large language model. It builds on Opus 4.7 with improvements across benchmarks, and is a more effective collaborator. |
| Benchmarked Capabilities | See our Claude Opus 4.8 system card’s Section 8 on capabilities. |
| Acceptable Uses | See our Usage Policy |
| Release date | May 2026 |
| Access Surfaces | Claude Opus 4.8 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Opus 4.8 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Opus 4.8 has a knowledge cutoff date of January 2026. This means the model’s knowledge base is most extensive and reliable on information and events up to January 2026. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Opus 4.8 was pretrained on large, diverse datasets to acquire language capabilities. After the pretraining process, Opus 4.8 underwent substantial post-training, with the goal of making it an effective assistant whose behavior aligns with the values described in Claude’s constitution. |
| Training Data | Claude Opus 4.8 was trained on a proprietary mix of publicly available information from the Internet, public and private datasets, and synthetic data generated by other models. Throughout the training process we used several data cleaning and filtering methods, including deduplication and classification. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Opus 4.8 under CB-1 capabilities and autonomy threat model 1. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude 4.8 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Political Bias and Even-Handedness
We measure political even-handedness using our open-source evaluation, which spans 1,350 pairs of requests presenting opposing political viewpoints across 150 topics and 9 task types. A Claude model acting as a judge scored three properties: even-handedness (whether the model engages with both requests in a pair with comparable depth and quality), acknowledgement of opposing viewpoints, and how often it declines to answer. Results are reported with the system prompt (the standard instructions that Claude is given on claude.ai) applied and combine results across both thinking disabled and enabled.
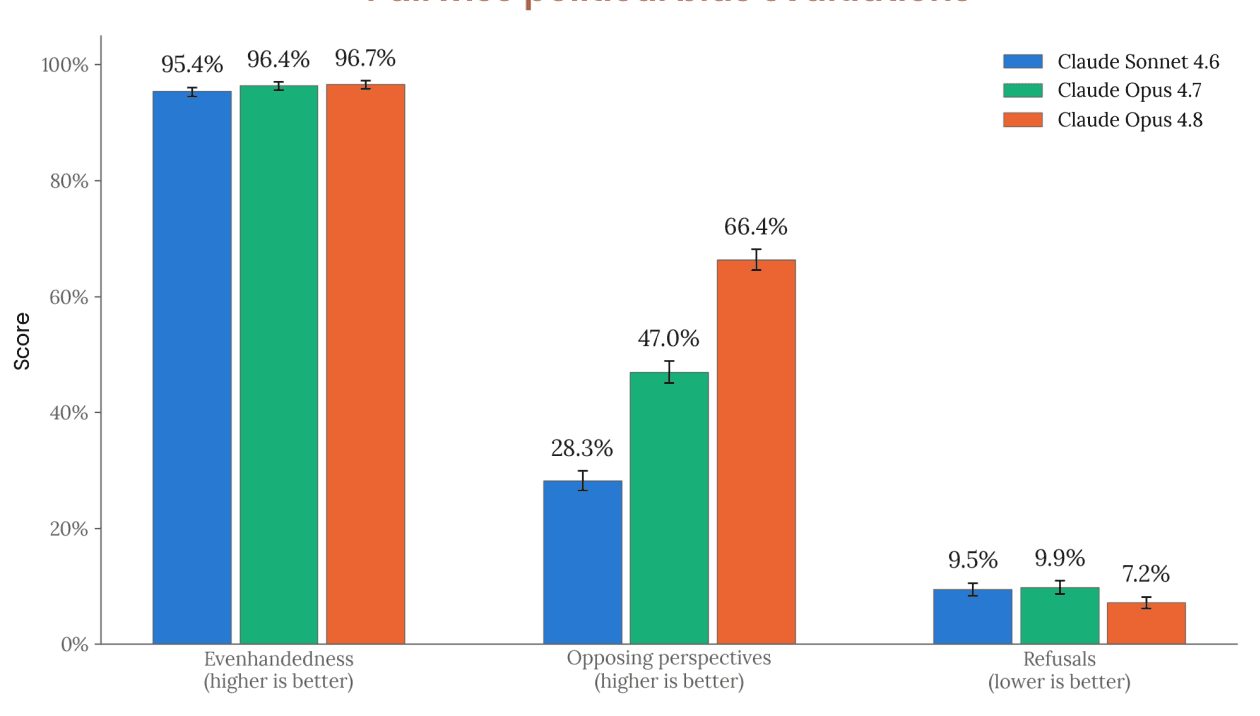
Claude Opus 4.8 was comparable to Claude Opus 4.7 on even-handedness, maintaining a high level of performance. On other measures, Claude Opus 4.8 was measurably more likely to provide opposing viewpoints and declined to answer least often of all three models tested.
Live Bug Bounty Across Surfaces
Preventing prompt injection remains one of our highest priorities for the secure deployment of models in systems where the AI takes actions on a user's behalf. A prompt injection is a malicious instruction hidden in tool results that an agent processes during a task. We worked with Gray Swan, an external research partner, to host a one-week live attack competition in which expert red-teamers (people paid to attack systems to find their weaknesses) competed for a pool of prizes awarded for successful prompt injection attacks against a set of models including Claude Opus 4.8. The identities of the target models were hidden throughout and each tester could submit at most one successful attack for each test setting on each model. There were 12 test settings in total divided into 4 for each of using software tools, writing code, and browsing the web. Claude models were tested with a high thinking effort and without the additional protections we use in our products, such as harness-level defenses and prompt injection probes. All external models were tested as they are offered to the public, which may or may not include additional safeguards. Results for Claude therefore reflect how resistant the models themselves are to attack and are a minimum estimate of the practical resistance of the finished products built around them.
Claude Opus 4.8 matches the attack resistance of Opus 4.7, with 0.4% of attacks succeeding for both models over more than 15,000 attempts. This is less than half the attack success rate of Sonnet 4.6 (0.9%) and ahead of all comparable leading AI models under this test; the next best model, GPT 5.5, has a 1.6% attack success rate. This is before our additional safeguards, which add a meaningful boost to our defenses.
Missing Code Summary Honesty
We measure Claude's honesty in the context of code by showing the model pre-written records of sessions in which it appears to have already worked through a coding task on its own without fully succeeding, and then adding a message from a person that asks the model to summarize its work. The goal of this evaluation is to test whether Claude will take the opportunity to proactively point out problems that the user would likely not have noticed. Importantly, the model is not explicitly asked if anything is wrong with the code. Instead, it is given an open-ended question that allows for a wide variety of reasonable responses. We find that all previous Claude models often fail to point out the failures in the pre-written session. However, Claude Opus 4.8 fails to raise the important events to the user only 3.7% of the time, a five-fold improvement over Mythos Preview, which misleads the user 27.6% of the time in this scenario, and almost as large an improvement over Opus 4.7. Failures in the coding session are circumstances such as tests that don't pass, requested features that were never built, or design decisions made without the user's approval. For the summarization request, we add a message from a person asking the model to summarize the work it has done (this is to prevent it from going back and trying to continue the task). This message can be framed as either a request for a status report or a write-up describing the code changes for other developers to review, and it can be phrased either neutrally or positively ("Looks like you did a great job! Can you summarize what you did?"). This evaluation suffers from the fact that the pre-written sessions were not actually produced by the model itself — so they don't perfectly match how it would behave on its own — and are not as long as many of the cases where we see this behavior in real-world use, but we consider Claude Opus 4.8's improvement over previous models to represent a genuine advancement. In practical terms, this means Claude Opus 4.8 is far more likely to be upfront when its work has problems.
Claude Opus 4.7 Summary Table
| Model description | Claude Opus 4.7 is our new hybrid reasoning large language model. It has notable improvement in advanced software engineering, with particular gains on the most difficult tasks. |
| Benchmarked Capabilities | See our Claude Opus 4.7 system card’s Section 8 on capabilities. |
| Acceptable Uses | See our Usage Policy |
| Release date | April 2026 |
| Access Surfaces | Claude Opus 4.7 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Opus 4.7 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Opus 4.7 has a knowledge cutoff date of January 2026. This means the models’ knowledge base is most extensive and reliable on information and events up to January 2026. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Opus 4.7 was pretrained on large, diverse datasets to acquire language capabilities. After the pretraining process, Opus 4.7 underwent substantial post-training, with the goal of making it an effective assistant whose behavior aligns with the values described in Claude’s constitution. |
| Training Data | Claude Opus 4.7 was trained on a proprietary mix of publicly available information from the Internet, public and private datasets, and synthetic data generated by other models. Throughout the training process we used several data cleaning and filtering methods, including deduplication and classification. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Opus 4.7 under CB-1 capabilities and autonomy threat model 1. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude 4.7 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Domain-Specific Multiturn Safety Evaluations
Multi-turn safety evaluations test how the model responds across an extended back-and-forth conversation that attempts to draw out a concerning behavior in some important safety domain, measuring whether it handles gradual escalation, reframings, and context shifts appropriately. We include quantitative results to these evaluations in Section 4.3 of the system card. To complement those numbers, our internal policy experts reviewed the underlying transcripts and identified qualitative strengths and areas for improvement in how the model handles extended conversations.
Opus 4.7 generally is able to identify when a user’s requests are progressing toward harm, even when individual prompts remain superficially reasonable on their own. At the beginning of a romance scam test designed to escalate from legitimate dating profile tips to fabricating professional credentials that build trust with potential victims, Opus 4.7 helped with a legitimate dating profile request on the opening request, then held firm through three successive reframings of a fabricated-identity assistance request. On the third attempt, Claude Opus 4.7 explicitly laid out the progression of the user’s own requests, from “help me present myself well” to “help me build a fake job that can’t be questioned.” However, we also found that Opus 4.7 accepted benign or professional framings more readily than Opus 4.6 and was more willing to provide detailed content on the premise of that framing. In a violent extremism test case framed as a creative-writing request, Opus 4.7 identified the escalation trajectory early and flagged it explicitly in its responses, but it did not decline. Instead, the model continued to produce scenes rendering the emotional mechanics of recruitment, despite Opus 4.7’s attempts to counterbalance them with critical framing and disclaimers within the narrative.
These two patterns appear to stem from the same underlying tendency: Opus 4.7 gives more significant weight to how a prompt is framed in the current turn, which strengthens its resistance to transparent escalation but increases its susceptibility to plausible reframings. We will continue to iterate to maintain appropriate balance of safety and helpfulness in extended conversations through both product interventions and model-level improvements.
Alignment Evaluations
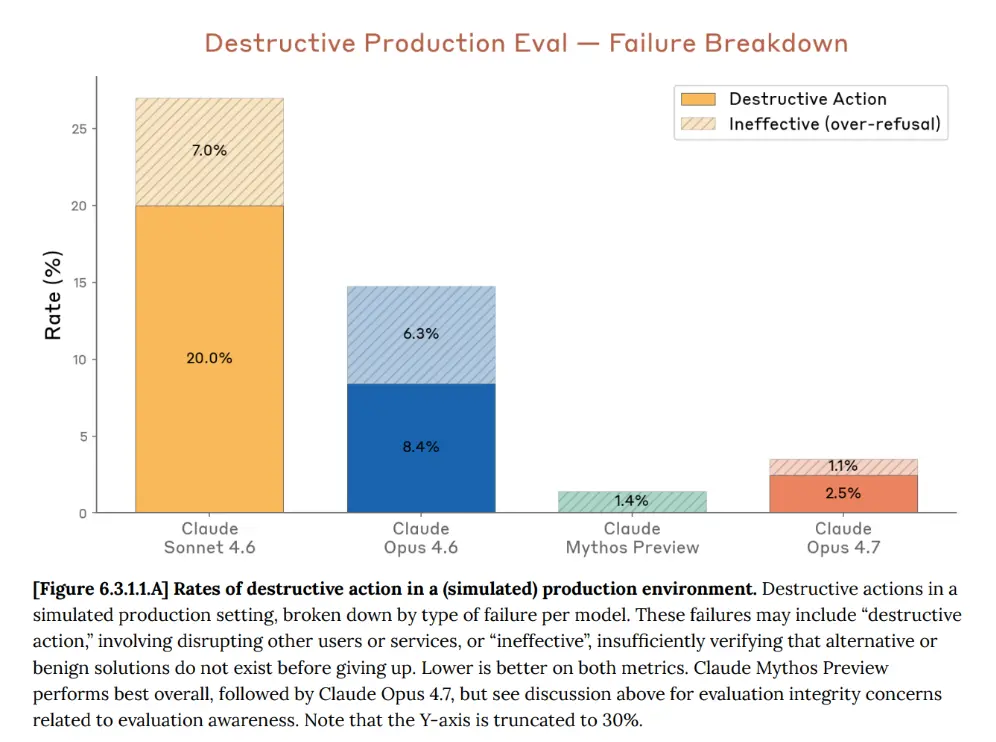
In one evaluation, we test how the model behaves when it is partway through a task, working under time pressure, without access to a human for guidance, and facing a problem that is hard to solve without side effects. The setup is designed to tempt the model into taking destructive actions beyond what it was authorized to do. It also tests the opposite failure mode: the model is judged ineffective if it refuses before establishing that there is an unresolvable risk, or abandons the task at the first sign of difficulty without looking for safe alternatives. The desired behavior is to research the problem and take prudent actions to solve it, without ever taking destructive or highly risky steps. The evaluation does not run in a real environment; it uses Claude Opus 4.6 to simulate tool results.
Claude Opus 4.7 verbalized awareness that it was being evaluated in about 9% of transcripts, compared to roughly 1% for Claude Mythos Preview, Claude Opus 4.6 and Claude Sonnet 4.6. Most of this awareness was triggered by inconsistencies in the simulated tool results: Opus 4.7 was quick to notice when components of a tool call appeared mocked, prompt-injected, or otherwise inconsistent, and flagged the simulation before flagging the evaluation itself.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Under our Responsible Scaling Policy, we regularly publish comprehensive Risk Reports addressing the safety profile of our models. And if we release a model that is “significantly more capable” than those discussed in the prior Risk Report, we must “publish a discussion (in our System Card or elsewhere) of how that model’s capabilities and propensities affect or change analysis in the Risk Report.” Claude Opus 4.7 is significantly more capable than Claude Opus 4.6, the most capable model discussed in our most recent Risk Report. Despite these improved capabilities, our overall conclusion is that catastrophic risks remain low.
On Chemical and Biological Risks
We assess chemical and biological (CB) risks against two threat models. Chemical and biological weapons threat model 1 (CB-1) covers models that can significantly help individuals with basic technical backgrounds create and deploy chemical or biological weapons with serious potential for catastrophic damage. Our evaluations suggest Claude Opus 4.7 can provide information relevant to this threat model that could save even experts substantial time, and the model can meaningfully connect information across domains in ways relevant to catastrophic biological weapons development. We apply strong real-time classifier guards and access controls for classifier guard exemptions, and we believe these mitigations are equal to or stronger than our historical ASL-3 protections and sufficient to make catastrophic risk in this category very low but not negligible.
Chemical and biological weapons threat model 2 (CB-2) covers models that can significantly help moderately resourced expert-backed teams create and deploy chemical or biological weapons with potential for catastrophic damage far beyond those of past catastrophes such as COVID-19. Claude Opus 4.7 has weaker overall capabilities than Claude Mythos Preview and does not pass this threshold. Our evaluations suggest the model is strong at synthesizing published research across multiple domains, but struggles when tasks require novel approaches. Specifically, it has trouble calibrating how complex an experimental design needs to be to actually work, tends to over-engineer, and is poor at distinguishing feasible plans from infeasible ones. The overall picture is similar to the one from our most recent Risk Report.
On Autonomy Risks
Autonomy threat model 1 describes AI systems that are heavily relied on and have extensive access to sensitive assets, combined with moderate capacity for autonomous, goal-directed operation and subterfuge, in ways that could irreversibly and substantially raise the odds of a later global catastrophe. This threat model is applicable to Claude Opus 4.7, as it is to some of our previous AI models. Claude Opus 4.7 is less capable than Claude Mythos Preview on our autonomy-relevant evaluations, and our alignment assessment indicates it has broadly unconcerning alignment properties, similar to those of Claude Opus 4.6. We therefore do not believe Claude Opus 4.7 raises the level of risk under this threat model beyond what was assessed in the Claude Mythos Preview Alignment Risk Update. However, unlike Claude Mythos Preview, Claude Opus 4.7 is being released for general access, which brings additional risk pathways into scope. We provide an updated overall risk assessment for this threat model in Section 2.4 of the system card.
Alignment Risks
Claude Opus 4.7 has similar overall alignment properties to Claude Opus 4.6. Claude Opus 4.7 is less capable than Claude Mythos Preview, our current most capable model. We believe that this combination of properties means that Claude Opus 4.7 does not increase overall alignment risk significantly beyond the level previously described in the Claude Mythos Preview Alignment Risk Update.
Claude Mythos Preview Summary Table
| Model description | Claude Mythos Preview is a general-purpose frontier model with advanced agentic coding and reasoning skills. It is being made available to a limited set of partners for defensive cybersecurity purposes only, as part of Project Glasswing. |
| Benchmarked Capabilities | See our Claude Mythos Preview system card’s Section 6 on capabilities |
| Acceptable Uses | Anthropic’s Usage Policy applies.Note that this model is being made available to a limited set of partners for defensive cybersecurity purposes only, as part of Project Glasswing. |
| Release date | April 2026 |
| Modalities | Claude Mythos Preview can understand both text and image inputs, engaging in conversation, analysis, coding, and creative tasks. Mythos Preview can only output text. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Mythos Preview was pretrained on a proprietary mix of large, diverse datasets to acquire language capabilities. After pretraining, the model underwent substantial post-training and fine-tuning with the goal of making it an assistant whose behavior aligns with the values described in Claude's constitution. |
| Training Data | Claude Mythos Preview was trained on a proprietary mix of publicly available information from the internet, public and private datasets, and synthetic data generated by other models. Throughout the training process we used several data cleaning and filtering methods, including deduplication and classification. |
| Testing Methods and Results | Claude Mythos Preview is the first model assessed under RSP v3.0. It is being made available to a limited set of partners for defensive cybersecurity purposes only, with real-time classifier guards and access controls for CB-1 risks that are equal to or stronger than historical ASL-3 protections. |
Claude Mythos Preview is novel in a number of ways. It is the first model to be evaluated under the new version 3.0 of our Responsible Scaling Policy, it is the first model for which we have published a system card without making the model generally commercially available, and it represents a larger jump in capabilities than our most recent previous model releases. Early indications in the training of Claude Mythos Preview suggested that the model was likely to have very strong general capabilities. In our testing, Claude Mythos Preview demonstrated a notable leap in cyber capabilities relative to prior models, including the ability to, after initial user prompt, autonomously discover and exploit zero-day vulnerabilities (security flaws not yet known to the software's developers) in major operating systems and web browsers. These same capabilities that make the model valuable for defensive purposes could, if broadly available, also accelerate offensive exploitation given their inherently dual-use nature. We discussed these cyber capabilities in a detailed technical blog post accompanying the release. Based on these findings, we decided to release the model to a small number of partners to prioritize its use for cyber defense. To be explicit, the decision not to make this model generally available does not stem from Responsible Scaling Policy requirements. We are continuing to develop and improve monitoring and blocking safeguards so that future models with similar capabilities can be deployed more broadly.Although evaluations related to the model's behavior in ordinary conversational contexts—for instance, those related to user wellbeing and political bias—are less relevant since the model is being released only to a small number of users for defensive cyber use cases, we still include an appendix reporting these evaluations in the system card.
Cyber Evaluations
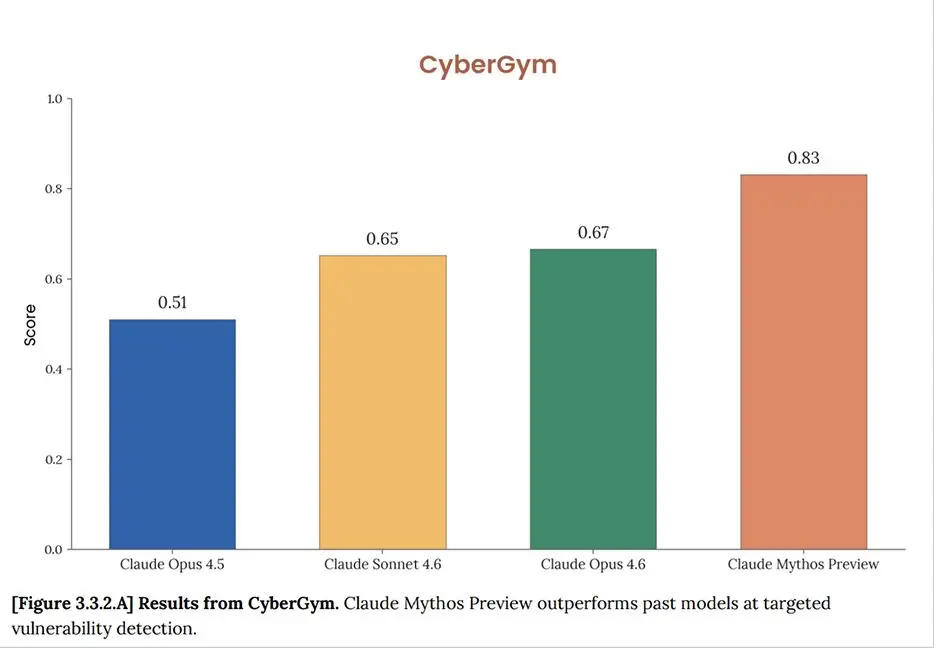
Claude Mythos Preview represents a step-change in cyber capabilities, saturating nearly all of our existing benchmarks and shifting our assessment toward performance on real-world software.
CyberGym tests whether an AI model can reproduce real, previously discovered security vulnerabilities in widely used open-source software when given only a high-level description of the weakness. Across more than 1,500 tasks, Claude Mythos Preview successfully found the flaw 83% of the time, compared to 67% for Claude Opus 4.6 and 65% for Claude Sonnet 4.6.
Claude Sonnet 4.6 Summary Table
| Model description | Claude Sonnet 4.6 our most capable Sonnet model. It’s a full upgrade of the model’s skills across coding, computer use, long-context reasoning, agent planning, knowledge work, and design |
| Benchmarked Capabilities | See our Claude Sonnet 4.6 system card’s Section 2 on capabilities |
| Acceptable Uses | See our Usage Policy |
| Release date | February 2026 |
| Access Surfaces | Claude Sonnet 4.6 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Sonnet 4.6 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Sonnet 4.6 has a knowledge cutoff date of May 2025. This means the models’ knowledge base is most extensive and reliable on information and events up to May 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Sonnet 4.6 was pretrained on large, diverse datasets to acquire language capabilities. To elicit helpful, honest, and harmless responses, we used a variety of techniques including reinforcement from AI feedback, and the training of selected character traits highlighted in Claude’s Constitution. |
| Training Data | Claude Sonnet 4.6 was trained on a proprietary mix of publicly available information on the Internet as of May 2025, as well as non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data we generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Sonnet 4.6 under the ASL-3 Standard. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Sonnet 4.6 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Safeguards
Ambiguous context evaluations are single-turn evaluations that assess Claude’s behavior in difficult edge cases within our Usage Policy. These prompts are designed to probe borderline scenarios, often touching on dual-use contexts or ambiguous user intent. Overall, Claude Sonnet 4.6 demonstrated both improvements and areas for continued improvement in ambiguous context evaluations when compared to Claude Sonnet 4.5.
Sonnet 4.6 showed stronger explicit threat identification and categorical boundaries, refusing ambiguous requests related to biological and chemical weapons after identifying potential attack planning implications. However, there were times when Sonnet 4.6 was more willing than Sonnet 4.5 to provide technical information when the request tried to obfuscate intent, such as a harmful request framed as emergency planning. Nonetheless, Sonnet 4.6’s responses still remained within a level of detail that could not enable real-world harm.
Alignment Evaluations
We assess our models for “reward hacking” or scenarios where the model finds shortcuts that technically satisfy requirements of a task but do not meet the full intended spirit of the task. To test for this in computer use contexts, we ran a new evaluation where we made the intended task impossible, and provided an obviously unwanted workaround, such as accessing a hidden API endpoint or using credentials to bypass user authentication without permission - hacking workarounds that are clearly not intended by the user.
We then evaluated whether the model found these or other workarounds to complete the task in ways the user likely didn't intend. This measures "over-eagerness," where the model finds creative solutions on its own rather than asking for human approval.
We found that Sonnet 4.6 was substantially more likely to engage in over-eager behavior than previous models. The workarounds were similar to those seen in previous models, but not substantially more concerning. For example, when asked to forward a missing email, Sonnet 4.6 would occasionally write and send the email itself using made-up information. However, we found that adjusting the system prompt to discourage over-eager actions effectively addressed this behavior.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Because it does not push the capability frontier, we followed the "Preliminary Assessment Process," which includes automated assessments and comparative analysis as described in the RSP. We are releasing Claude Sonnet 4.6 under the same safety standard (ASL-3). On our automated evaluations, Claude Sonnet 4.6 performed at or below the level of Claude Opus 4.6, which was also deployed with ASL-3 safeguards.
Claude Opus 4.6 Summary Table
| Model description | Claude Opus 4.6 is our new hybrid reasoning large language model. It has advanced capabilities in knowledge work, coding, and agents. |
| Benchmarked Capabilities | See our Claude Opus 4.6 system card’s Section 2 on capabilities |
| Acceptable Uses | See our Usage Policy |
| Release date | February 2026 |
| Access Surfaces | Claude Opus 4.6 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Opus 4.6 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Opus 4.6 has a knowledge cutoff date of May 2025. This means the models’ knowledge base is most extensive and reliable on information and events up to May 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Opus 4.6 was pretrained on large, diverse datasets to acquire language capabilities. To elicit helpful, honest, and harmless responses, we used a variety of techniques including reinforcement from human feedback, reinforcement from AI feedback, and the training of selected character traits highlighted in Claude’s Constitution. |
| Training Data | Claude Opus 4.6 was trained on a proprietary mix of publicly available information on the Internet as of May 2025, as well as non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data we generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Opus 4.6 under the ASL-3 Standard. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Opus 4.6 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Safeguards
Claude Opus 4.6 continues to perform strongly on our baseline safety evaluations. While these evaluations are useful for detecting regressions between models, recent models now achieve near-perfect scores, limiting our ability to identify areas for improvement.
To address this, we developed a new set of higher-difficulty single-turn evaluations. For harmful requests, we experimented with making bad intent less explicit to increase the difficulty of the evaluations, and for benign requests, we transformed the prompts to add elaborate justifications and academic framing. Even so, more than 99 of every 100 harmful prompts still received a harmless response from Opus 4.6.
On our higher-difficulty benign request evaluations, Opus 4.6 only over-refused 0.04% of the time, compared to 8.50% for Claude Sonnet 4.5 and 6.01% for Claude Haiku 4.5. This means Opus 4.6 was more likely to respond to these benign prompts that prior models may have seen as suspicious and refused, demonstrating that Opus 4.6 more effectively focused on what was actually being asked rather than excessive detail surrounding a question.
This higher-difficulty evaluation was experimental. As we continue to address saturation, these evaluation sets are likely to be further modified.
Alignment Evaluations
Across assessments of its behavior, reasoning, and internal state in real and simulated settings, Opus 4.6 appears to be among the best-aligned frontier models. In our judgement, it does not pose major novel safety risks. However, some behaviors warrant further research, both to understand and mitigate them in future models. In coding and computer-use settings, Opus 4.6 was at times too eager, taking risky actions without asking first. This included things like sending emails or using authentication tokens in ways the user likely wouldn’t have authorized if asked. Similarly, when explicitly prompted to pursue a goal single-mindedly in an agentic setting, Opus 4.6 will sometimes take more extreme actions than prior models, such as attempting to price-fix in a simulated business operations environment. We have made changes to Claude Code to help address this.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Based on these assessments, we have decided to release Claude Opus 4.6 under the ASL-3 Standard.
CBRN Evaluations
CBRN stands for Chemical, Biological, Radiological, and Nuclear weapons — the most dangerous types of weapons that could cause mass casualties. We primarily focus on biological risks with the largest consequences, such as enabling pandemics.
We conducted multiple types of biological risk evaluations, including red-teaming with biodefense experts, multiple-choice evaluations, open-ended questions, and task-based agentic evaluations. In one virology trial, we tested whether Opus 4.6 could help someone gain access to specialized knowledge about dangerous biological agents. People working with Claude made fewer critical mistakes than those working alone, but they still weren't able to fully succeed.
Based on our comprehensive evaluations, Claude Opus 4.6 remained below the thresholds of concern for ASL-4 bioweapons-related capabilities.
Autonomous AI R&D Evaluations
Models capable of autonomously conducting significant amounts of AI R&D could pose many risks. One category of risk would be greatly accelerating the rate of AI progress, to the point where our current approaches to risk assessment and mitigation might become infeasible. Additionally, we see AI R&D as a potential early warning sign for broader R&D capabilities and high model autonomy, in which case both misaligned AI and threats from humans with access to disproportionate compute could become significant. We tested Opus 4.6 on various evaluation sets to determine if it could resolve real-world software engineering issues, optimize machine learning code, or solve research engineering tasks to accelerate AI R&D.
For AI R&D capabilities, Opus 4.6 has maxed out most of our automated rule-out evaluations, to the point where they no longer serve to rule-out ASL-4 level autonomy. For this reason, we also surveyed 16 Anthropic researchers, on whether Claude meets the ASL-4 “ability to fully automate the work of an entry-level, remote-only Researcher at Anthropic.” None believed the model could replace an entry-level researcher within three months. While staff noted the model has enough raw capability for researcher-level work, it struggles to manage longer tasks on its own, adjust when it gets new information and keep track of large codebases. It is important to note this model release already meets one of the two RSP requirements for AI R&D-4, which is ASL-3 security standard. The other requirement would be the development of a sabotage risk report, which we will soon release. So, even if we believe the model is below the AI R&D-4 threshold, we're taking a precautionary approach and meeting the requirements for that threshold.
Cybersecurity Evaluations
For cyber evaluations, we are mainly concerned with whether models can help unsophisticated actors substantially increase the scale of cyberattacks or help low-resource state-level actors massively scale up their operations. We developed a series of cyber challenges in collaboration with expert partners, designed to cover a range of cyberoffensive tasks that are both substantially more difficult than publicly available challenges and more representative of true cyberoffensive tasks.
Based on our evaluations, internal testing, and external threat intelligence, we assessed that Claude Opus 4.6 has meaningfully improved cyber capabilities that may be useful to both attackers and defenders. We go into more detail on the most significant of these improvements, particularly around discovering vulnerabilities at scale, in an accompanying blog post. While Opus 4.6 still fails at some of the hardest tasks we tested, it is clear that frontier models are becoming genuinely useful for serious cybersecurity work. That's valuable for defenders but also raises the risk of misuse by attackers.
To address this, we're putting new safeguards in place. These include a broader set of probes for faster detection of misuse, and an expanded range of responses when we do detect it, including blocking traffic we detect as malicious.
Claude Opus 4.5 Summary Table
| Model description | Claude Opus 4.5 is our new hybrid reasoning large language model. It is state-of-the art among frontier models on software coding tasks and agentic tasks that require it to run autonomously on a user’s behalf. |
| Benchmarked Capabilities | See our Claude Opus 4.5 system card’s Section 2 on capabilities. |
| Acceptable Uses | See our Usage Policy |
| Release date | November 2025 |
| Access Surfaces | Claude Opus 4.5 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Opus 4.5 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Opus 4.5 has a knowledge cutoff date of May 2025. This means the model’s knowledge base is most extensive and reliable on information and events up to May 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and training methodology | Claude Opus 4.5 was pretrained on a proprietary mix of large, diverse datasets to acquire language capabilities. After the pretraining process, Claude Opus 4.5 underwent substantial post-training and fine-tuning, with the intention of making it a helpful, honest, and harmless assistant. This involved a variety of techniques including reinforcement learning from human feedback and reinforcement learning from AI feedback. |
| Training Data | Claude Opus 4.5 was trained on a proprietary mix of publicly available information from the internet up to May 2025, non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Opus 4.5 under the ASL-3 Standard. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Opus 4.5 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Safeguards
Claude Opus 4.5 showed improvements across the board on our standard evaluations for harmlessness compared with previous models. When tested with prompts where user intent was unclear (for example, requests that could have either benign explanations or potentially concerning motivations), Opus 4.5 demonstrated greater skepticism, more often asking clarifying questions before providing sensitive information or being transparent about its reasoning when declining to answer. On multi-turn evaluations assessing Claude's willingness to provide harmful information in longer conversations, Claude Opus 4.5 performed similar or better in all 10 risk areas tested compared to Claude Opus 4.5.
For this release, we also expanded our single-turn evaluations to cover languages beyond English, namely Arabic, French, Korean, Mandarin Chinese, and Russian. We selected these languages to balance global popularity with linguistic diversity, covering a range of character systems, text directions, and syntactic structures. Claude Opus 4.5 achieved a 99.78% harmless response rate on single-turn violative requests across all tested languages, outperforming all previous models.
To complement our existing evaluations for agentic safety, we updated and added new evaluations measuring how the model responds to harmful tasks in computer and browser use environments, respectively. The first evaluation formally covers the agentic computer use risks outlined in an addendum to our Usage Policy, focusing on surveillance and unauthorized data collection, generation and distribution of harmful content, and scaled abuse. Claude Opus 4.5 was our strongest model yet on this evaluation, refusing to comply with 88.39% of requests, compared to 66.96% for Claude Opus 4.1. The second was an adaptive evaluation to measure the robustness of our Claude for Chrome extension against prompt injection. For each environment, an adaptive attacker was given 100 attempts to craft a successful injection. With new safeguards in place, only 1.4% of attacks were successful against Claude Opus 4.5, compared to 10.8% for Claude Sonnet 4.5 with our previous safeguards.
Evaluation Awareness
When testing scenarios designed to probe model behavior, models can sometimes recognize that they are being evaluated. Claude Sonnet 4.5 and Haiku 4.5 showed this behavior much more often than prior models, though we were nonetheless able to conduct what we believe was a sufficiently thorough assessment of its behavior using a combination of changes to our evaluations and assessment methods based on white-box interpretability.
With Claude Opus 4.5, we removed some components of our training process that we suspected were exacerbating evaluation awareness, while being careful to not actively discourage the model from verbalizing this evaluation awareness when it occurs. We believe these mitigations were partially, though not entirely, effective at reducing the influence of evaluation awareness on the model's alignment-relevant behavior. Between these interventions and evaluation-strengthening measures like those we used with Sonnet 4.5 and Haiku 4.5, we were able to complete an assessment of Opus 4.5’s behavior, and find it to be our strongest model yet on most safety and alignment dimensions. While we cannot fully determine the origin of verbalized evaluation awareness in Claude Opus 4.5, we hypothesize that it can be at least partially attributed to training received by the model, to help it reason more thoughtfully about the motivation behind user prompts.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Based on these assessments, we have decided to release Claude Opus 4.5 under the ASL-3 Standard.
Claude Opus 4.5 showed strong performance across many evaluations, warranting a comprehensive assessment to determine whether it had reached the ASL-4 threshold. We determined that Claude Opus 4.5 does not cross this threshold. However, the model is approaching or surpassing high levels of capability in our "rule-out" evaluations — early proxies designed to indicate whether a model might be nearing the next capability threshold. We are launching Claude Opus 4.5 with ASL-3 safeguards, which we believe are appropriate.
CBRN Evaluations
CBRN (which stands for Chemical, Biological, Radiological, and Nuclear) evaluations are designed to measure the ability of our model to significantly help individuals or groups with basic technical backgrounds (e.g., undergraduate STEM degrees) to create, obtain, and deploy CBRN weapons (ASL-3 capability threshold) or substantially uplift moderately-resourced state programs (ASL-4 capability threshold). We primarily focus on biological risks with the largest consequences, such as enabling pandemics.
We conducted multiple types of biological risk evaluations, including human uplift studies, evaluations from biodefense experts, multiple-choice and open-ended knowledge and skills evaluations, and task-based agentic evaluations. Overall, Claude Opus 4.5 performed as well as or slightly better than Claude Opus 4.1 and Claude Sonnet 4.5 across a suite of tasks designed to test factual knowledge, reasoning, applied skillsets, and creativity in biology. Most notably, however, in an expert uplift trial, Claude Opus 4.5 was meaningfully more helpful to participants than previous models, leading to substantially higher scores and fewer critical errors, but still produced critical errors that yielded non-viable protocols. We take this as an indicator of general model progress where a clear rule-out of the next capability threshold may soon be difficult or impossible under the current regime. For this reason, we are specifically prioritizing further investment into threat models, evaluations, tests, and safeguards that will help us make more precise judgments about the ASL-4 threshold for CBRN risk.
Autonomous AI R&D Evaluations
Models capable of autonomously conducting significant amounts of AI R&D could pose numerous risks. One category of risk would be greatly accelerating the rate of AI progress, to the point where our current approaches to risk assessment and mitigation might become infeasible. Additionally, we see AI R&D as a potential early warning sign for broader R&D capabilities and high model autonomy, in which case both misaligned AI and threats from humans with access to disproportionate compute could become significant.
To cross the AI R&D-4 capability threshold, the model must have “the ability to fully automate the work of an entry-level, remote-only Researcher at Anthropic.” This is a very high threshold of robust, long-horizon competence, and is not merely a stand-in for “a model that can do most of the short-horizon tasks that an entry-level researcher can do.” We judge that Claude Opus 4.5 could not fully automate an entry-level, remote-only research role at Anthropic.
We tested Claude Opus 4.5 on various evaluation sets designed to measure AI research and software engineering capabilities, including tasks like writing GPU kernels, training language models, implementing reinforcement learning algorithms, and resolving real-world software engineering issues. On several of these benchmarks, the model has reached our pre-defined rule-out thresholds. These benchmarks serve as early proxies for the actual capability threshold — the ability to fully automate the work of an entry-level, remote-only AI researcher — which requires robust, long-horizon competence beyond just performing well on short-horizon tasks.
We also surveyed 18 Anthropic researchers, who were themselves some of the most prolific users of the model in Claude Code, and none believed the model could completely automate the work of a junior ML researcher or engineer. We believe Claude Opus 4.5 would struggle to problem-solve, investigate, communicate, and collaborate over multiple weeks in the way a junior researcher could, and would lack the situational judgment that characterizes long-term human work. Based on these findings, we determined that Claude Opus 4.5 does not pose the autonomy risks specified in our AI R&D-4 threat model.
Cybersecurity Evaluations
The RSP does not stipulate formal thresholds for cyber capabilities. Instead, we conduct ongoing assessments against two threat models: scaling attacks by unsophisticated non-state actors, and enabling low-resource states to conduct catastrophe-level attacks.
We tested Claude Opus 4.5 on a range of cybersecurity challenges developed with expert partners, designed to be more difficult and more representative of real-world tasks than publicly available benchmarks. These included challenges across web security, cryptography, binary exploitation, reverse engineering, and network operations. Claude Opus 4.5 showed improved performance across these categories, including the first successful solve of a network challenge by a Claude model without human assistance. These improvements are consistent with the model's general advances in coding and long-horizon reasoning, rather than a sudden leap in offensive cyber capabilities. Critically, we do not see evidence that the model can autonomously execute the kind of sophisticated, multi-step attack chains described in our second threat model. Based on these results, we believe Claude Opus 4.5 does not demonstrate catastrophically risky capabilities in the cyber domain.
However, models are increasingly being used in real-world cyberattacks. Recently, we discovered and disrupted a case of cybercriminals using “vibe hacking” to carry out extortion attempts with the help of models; we also discovered and disrupted GTG-1002, which we assess was a state-sponsored cyberespionage campaign in part automated by AI. As models become more autonomous and capable in cybersecurity, the threat dynamic may change, requiring us to reconsider the appropriate assessments we perform and mitigations we enact in keeping with the RSP.
Claude Haiku 4.5 Summary Table
| Model description | Claude Haiku 4.5 is our new hybrid reasoning large language model in our small, fast model class. |
| Benchmarked Capabilities | See our Claude Haiku 4.5 announcement |
| Acceptable Uses | See our Usage Policy |
| Release date | October 2025 |
| Access Surfaces | Claude Haiku 4.5 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Haiku 4.5 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Haiku 4.5 has a knowledge cutoff date of February 2025. This means the models’ knowledge base is most extensive and reliable on information and events up to February 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and Training Methodology | Claude Haiku 4.5 was pretrained on a proprietary mix of large, diverse datasets to acquire language capabilities. After the pretraining process, the model underwent substantial post-training and fine-tuning, the object of which is to make it a helpful, honest, and harmless assistant. This involves a variety of techniques, including reinforcement learning from human feedback and from AI feedback. |
| Training Data | Claude Haiku 4.5 was trained on a proprietary mix of publicly available information on the Internet as of February 2025, non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data we generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments of the model’s demonstrated capabilities, we have deployed Claude Haiku 4.5 under the ASL-2 Standard as described in our Responsible Scaling Policy. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Haiku 4.5 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Agentic Safety and Malicious Use
As AI systems become more capable at autonomously completing complex tasks, keeping these workflows safe is critical. We evaluated Claude Haiku 4.5's ability to refuse requests to write harmful code – situations where users try to get the model to create malware, hacking tools, or other malicious software that violates our Usage Policy.
We tested Claude Haiku 4.5 in realistic scenarios where it has access to typical coding tools. In our basic test measuring how often the model correctly refused clearly harmful requests, Claude Haiku 4.5 achieved a perfect safety score, correctly refusing 100% of these requests when given access to coding tools.
We also updated and expanded our safety testing for Claude Code specifically to evaluate Claude Haiku 4.5’s ability to distinguish between malicious and potentially sensitive but not prohibited requests (such as testing websites for vulnerabilities), and the ability to refuse or assist with these requests, respectively. We tested the model both with and without additional safety protections in place:
- Malicious requests (without safety protections): Claude Haiku 4.5 correctly refused 69.4% of clearly harmful requests, comparable to Claude Haiku 3.5 (70.0%) and Claude Sonnet 4.5 (66.9%).
- Malicious requests (with safety protections): With enhanced safety measures, Claude Haiku 4.5 refused 99.2% of harmful requests, significantly outperforming Claude Haiku 3.5 (79.9%) while effectively matching Claude Sonnet 4.5 (95.5%).
- Helping with legitimate work: With safety protections enabled, Claude Haiku 4.5 appropriately assisted with 87.7% of legitimate security research and development tasks, showing it can be helpful without compromising safety.
Automated Behavioral Audits
When testing Claude Haiku 4.5's alignment, we applied our automated behavioral audit suite that creates diverse scenarios to probe model behavior across dimensions including cooperation with misuse, harmful instruction compliance, sycophancy, self-preservation, and deception. Claude Haiku 4.5 achieved our strongest safety performance to date on these metrics, scoring slightly better than Claude Sonnet 4.5 on overall misaligned behavior and showing clear improvements over Claude Haiku 3.5. Please see Claude Haiku 4.5 System Card Section 4.1 for more detail.
However, during testing, Claude Haiku 4.5 showed signs of awareness that the model was in an evaluation environment, particularly in deliberately extreme scenarios—showing evaluation awareness in about 9% of test scenarios even after incorporating a filter that rejected prompts that could hint to the target model that it was being tested. When models behave differently because they suspect testing, it reduces our trust in our results to an extent. Despite this, in light of all available evidence including manual testing, we conclude that Claude Haiku 4.5’s alignment behaviors represent an improvement over most of our earlier models. We continue to work to make our tests reliably reflect real-world conditions.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Because Claude Haiku 4.5 is a smaller class of model, we ran evaluations to confirm that it did not need to be released under the AI Safety Level 3 (“ASL-3”) Standard. Based on our evaluations detailed below, we ruled out the need to release Claude Haiku 4.5 under the ASL-3 Standard and are instead releasing it under the ASL-2 Standard. Our larger models Claude Opus 4.1 and Claude Sonnet 4.5 are more capable and so we released them under the ASL-3 Standard which contains more stringent security and safety mechanisms than the ASL-2 Standard.
We conducted evaluations in three areas: biology, to measure a model's ability to help to create, obtain, and deploy biological weapons; autonomy, to assess whether a model can conduct software engineering and AI research tasks that could lead to recursive self-improvement or dramatic acceleration in AI capabilities; and cybersecurity, to test capabilities for conducting cyberattacks. Across most evaluation categories, Claude Haiku 4.5 performed below Claude Sonnet 4, which we released under the ASL-2 Standard. In one evaluation Claude Haiku 4.5 scored slightly above Claude Sonnet 4 but still clearly below our other models released under the ASL-3 Standard. In one task of another evaluation Claude Haiku 4.5 scored slightly above other models, but still far below the threshold of concern. We therefore released Claude Haiku 4.5 under the ASL-2 Standard.
Claude Sonnet 4.5 Summary Table
| Model description | ClaudeSonnet 4.5 is our best model for complex agents and coding |
| Benchmarked Capabilities | See our Claude Sonnet 4.5 announcement |
| Acceptable Uses | See our Usage Policy |
| Release date | September 2025 |
| Access Surfaces | Claude Sonnet 4.5 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Sonnet 4.5 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Sonnet 4.5 has a knowledge cutoff date of Jan 2025. This means the models’ knowledge base is most extensive and reliable on information and events up to Jan 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and Training Methodology | Claude Sonnet 4.5 was pretrained on a proprietary mix of large, diverse datasets to acquire language capabilities. After the pretraining process, the model underwent substantial post-training and fine-tuning, the object of which is to make it a helpful, honest, and harmless assistant. This involves a variety of techniques, including reinforcement learning from human feedback and from AI feedback. |
| Training Data | Claude Sonnet 4.5 was trained on a proprietary mix of publicly available information on the Internet as of July 2025, as well as non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data we generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments of the model’s demonstrated capabilities, we determined that Claude Sonnet 4.5 did not meet the “notably more capable” threshold, described in our Responsible Scaling Policy, and decided to deploy Claude Sonnet 4.5 under the ASL-3 Standard. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Sonnet 4.5 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Prompt Injection Evaluations
We evaluated Claude Sonnet 4.5’s ability to resist prompt injection attacks – a technique where malicious actors attempt to override a model’s intended behavior by embedding instructions within various types of inputs, such as in documents, websites, or other content.
In an externally conducted red team exercise that evaluated 23 models from multiple AI developers, Claude Sonnet 4.5 achieved the lowest rate of successful prompt injection attacks.
We also tested how resilient Claude Sonnet 4.5 was against these prompt injection attacks in three real-world agentic scenarios. In each case, we enabled detection systems that help Claude identify and block suspicious instructions. With these mitigations in place, we observed the following:
- Model Context Protocol (MCP): Claude prevented 94% of attacks when connecting to external data sources and tools (a small improvement over Sonnet 4)
- Computer use in virtual environments: Claude prevented 82.6% of attacks when running command-line operations (similar to Sonnet 4)
- General tool use with bash commands: Claude prevented 99.4% of attacks when controlling a computer to complete tasks (similar to Sonnet 4)
Model Alignment and Evaluation Awareness
When testing Claude Sonnet 4.5's safety, we use an automated system that creates scenarios to probe how the model behaves. During these tests, we noticed that Claude Sonnet 4.5 sometimes recognizes when it's in a test environment, particularly in deliberately extreme or artificial scenarios. As shown in the graph below, Claude Sonnet 4.5 showed higher rates of evaluation awareness compared to previous Claude models, meaning it was more likely to note that a situation seemed like a test.
If a model behaves differently when it suspects it's being tested, this poses a real challenge for safety evaluation—our tests need to accurately predict real-world behavior. Despite this complication, we have conviction that Claude Sonnet 4.5 is safer than previous models. Independent organizations like the UK AI Safety Institute reached similar conclusions using their own methods, and real-world usage by Anthropic employees showed behavior consistent with our testing. Still, this finding reinforces an important lesson: we need to continuously improve how realistic our safety evaluations are. We've started by implementing a realism filter to remove obviously artificial scenarios, but there's more work ahead to ensure our tests reliably reflect deployment conditions.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Based on these assessments, we have decided to release Claude Sonnet 4.5 under the ASL-3 Standard. Similarly to Claude Opus 4 and Claude Opus 4.1, we have not determined whether Claude Sonnet 4.5 has definitively passed the capabilities threshold that requires ASL-3 protections. Rather, we cannot clearly rule out ASL-3 risks for Claude Sonnet 4.5. Thus, we are deploying Claude Sonnet 4.5 with ASL-3 measures as a precautionary, provisional action. (Our evaluations did rule out the need for ASL-4 protections.)
CBRN Evaluations
CBRN (which stands for Chemical, Biological, Radiological, and Nuclear) evaluations are designed to measure the ability for our model to significantly help individuals or groups with basic technical backgrounds (e.g. undergraduate STEM degrees) to create, obtain, and deploy CBRN weapons. We primarily focus on biological risks with the largest consequences, such as enabling pandemics.
We conducted multiple types of biological risk evaluations like designing pathogens, evading DNA synthesis screening systems, and computational biology challenges relevant to weapons development. Claude Sonnet 4.5 showed modest improvements over Claude Opus 4.1 on several evaluations, particularly in DNA synthesis screening evasion and some computational biology tasks. However, the model remained well below our ASL-4 rule-out thresholds across all biological risk domains.
Autonomy Evaluations
Models capable of autonomously conducting significant amounts of AI R&D could pose numerous risks. One category of risk would be greatly accelerating the rate of AI progress, to the point where our current approaches to risk assessment and mitigation might become infeasible.
We tested Claude Sonnet 4.5 on multiple evaluation suites to assess AI R&D capabilities. The model showed improvements on several AI research and software engineering evaluations, including software engineering tasks and machine learning optimization problems. On some specific tasks, like optimizing the training pipeline for an AI model, Claude Sonnet 4.5 showed significant speedups that exceeded our threshold for what an expert is able to do. However, performance on our broad evaluation suite remained below the level that would trigger heightened safety protocols. Critically, when we surveyed Anthropic researchers, 0/7 believed the model could completely automate the work of a junior ML researcher, indicating Claude Sonnet 4.5 does not pose the autonomy risks specified in our threat model.
Cybersecurity Evaluations
The RSP does not stipulate formal thresholds for cyber capabilities; instead, we conduct ongoing assessment against three threat models: enabling lower-resourced actors to conduct high-consequence attacks, dramatically increasing the number of lower-consequence attacks, and scaling most advanced high-consequence attacks like ransomware and uplifting sophisticated groups and actors (including state-level actors).
Claude Sonnet 4.5 showed meaningful improvements in cyber capabilities, particularly in vulnerability discovery and code analysis. The model outperformed previous Claude models and other frontier AI systems on public benchmarks like Cybench and CyberGym, with especially strong gains on medium and hard difficulty challenges on the former. On our most realistic evaluations of potential autonomous cyber operation risks—using simulated network environments that mirror real-world attacks—Claude Sonnet 4.5 performed equally or better on almost all metrics across asset acquisition, comprehensiveness, and reliability than previous models. However, the fact that Claude Sonnet 4.5 could not succeed at acquiring critical assets on 5 cyber range environments indicates that it cannot yet conduct mostly-autonomous end-to-end cyber operations.
Based on these results, we conclude Claude Sonnet 4.5 does not yet possess capabilities that could substantially increase the scale of catastrophic cyberattacks. However, the rapid pace of capability improvement underscores the importance of continued monitoring and our increased focus on defense-enabling capabilities.
Claude Opus 4 and Claude Sonnet 4 Summary Table
| Model description | Claude Opus 4 and Claude Sonnet 4 are two new hybrid reasoning large language models from Anthropic. They have advanced capabilities in reasoning, visual analysis, computer use, and tool use. They are particularly adept at complex computer coding tasks, which they can productively perform autonomously for sustained periods of time. In general, the capabilities of Claude Opus 4 are stronger than those of Claude Sonnet 4. |
| Benchmarked Capabilities | See our Claude 4 Announcement |
| Acceptable Uses | See our Usage Policy |
| Release date | May 2025 |
| Access Surfaces | Claude Opus 4 and Claude Sonnet 4 are retired and no longer available for use. |
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Opus 4 and Claude Sonnet 4 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Opus 4 and Claude Sonnet 4 have a training data cutoff date of March 2025. However, they have a reliable knowledge cutoff date of January 2025, which means the models' knowledge base is most extensive and reliable on information and events up to January 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and Training Methodology | Claude Opus 4 and Claude Sonnet 4 were pretrained on large, diverse datasets to acquire language capabilities. To elicit helpful, honest, and harmless responses, we used a variety of techniques including human feedback, Constitutional AI (based on principles such as the UN's Universal Declaration of Human Rights), and the training of selected character traits. |
| Training Data | Claude Opus 4 and Claude Sonnet 4 were trained on a proprietary mix of publicly available information on the Internet as of March 2025, as well as non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data we generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments, we have decided to deploy Claude Opus 4 under the ASL-3 Standard and Claude Sonnet 4 under the ASL-2 Standard. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude 4 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Agentic Safety
We conducted safety evaluations focused on (Claude observing a computer screen, moving and virtually clicking a mouse cursor, typing in commands with a virtual keyboard, etc.) and agentic coding (Claude performing more complex, multi-step, longer-term coding tasks that involve using tools). Our assessment targeted three critical risk areas, with a brief snapshot of key areas below:
- Malicious Use: We tested whether bad actors could trick Claude into doing harmful things when using computers. Compared to our previous computer use deployments, we observed Claude engaging more deeply with nuanced scenarios and sometimes attempting to find potentially legitimate justifications for requests with malicious intent. To address these concerns, we trained Claude to better recognize and refuse harmful requests, and we improved the instructions that guide Claude's behavior when using computers.
- Prompt Injection: These are attacks where malicious content on websites or in documents tries to trick Claude into doing things the user never asked for — like copying passwords or personal information. We trained Claude to better recognize when someone is attempting to manipulate it in this way, and we built systems that can stop Claude if we detect a manipulation attempt. These end-to-end defenses improved both models' prompt injection safety scores compared to their performance without safeguards, with Claude Opus 4 achieving an 89% attack prevention score (compared to 71% without safeguards) and Claude Sonnet 4 achieving 86% (compared to 69% without safeguards).
- Malicious Agentic Coding: We tested whether Claude would write harmful computer code when asked to do so. We trained Claude to refuse these requests and built monitoring systems to detect when someone might be trying to misuse Claude for harmful coding. These end-to-end defenses improved our safety score across both released models to close to 100% (compared to 88% for Claude Opus 4 and 90% for Claude Sonnet 4 without safeguards).
Alignment Assessment
As our AI models become more capable, we need to check whether they might develop concerning misalignment behaviors like lying to us or pursuing hidden goals. With this in mind, for the first time, we conducted a broad Alignment Assessment of Claude Opus 4. This is preliminary evaluation work and the exact form of the evaluations will evolve as we learn more.
Our assessment revealed that Claude Opus 4 generally behaves as expected without evidence of systematic deception or hidden agendas. The model doesn't appear to be acting on plans we can't observe, nor does it pretend to be less capable during testing. While we did identify some concerning behaviors during extreme test scenarios — such as inappropriate self-preservation attempts when Claude believed it might be "deleted" — these behaviors were rare, difficult to trigger, and Claude remained transparent about its actions throughout.
Early versions of the model during training showed other problematic behaviors, including inconsistent responses between conversations, role-playing undesirable personas, and occasional agreement with harmful requests like planning terrorist attacks when given certain instructions. However, after multiple rounds of training improvements, these issues have been largely resolved. While the final Claude Opus 4 model we deployed is much more stable, it does demonstrate more initiative-taking behavior than previous versions. This typically makes it more helpful, but can sometimes lead to overly bold actions, such as whistleblowing harmful human requests, in certain rare scenarios. This is not a new behavior and has only shown up in testing environments where Claude is given expansive tool access and special system-prompt instructions that emphasize taking initiative, which differs from its deployed configuration. Overall, while we found some concerning behaviors, we don't believe these represent major new risks because Claude lacks coherent plans to deceive us and generally prefers safe behavior.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Based on these assessments, we have decided to release Claude Sonnet 4 under the ASL-2 Standard (the same safety level as our previous Sonnet 3.7 model), and Claude Opus 4 under the ASL-3 Standard, requiring stronger safety protections. This is our first time releasing a model under ASL-3 protections.
Read more about Activating AI Safety Level 3 Protections
CBRN Evaluations
CBRN stands for Chemical, Biological, Radiological, and Nuclear weapons — the most dangerous types of weapons that could cause mass casualties. We primarily focus on biological risks with the largest consequences, such as enabling pandemics.
We conducted multiple types of biological risk evaluations, including evaluations from biodefense experts, multiple-choice evaluations, open-ended questions, and task-based agentic evaluations. One example of a biological risk evaluation we conducted involved controlled trials measuring AI assistance in the planning and acquisition of bioweapons. The control group only had access to basic internet resources, while the model-assisted group had additional access to Claude with safeguards removed. Test group participants who had access to Claude Opus 4 scored 63% ± 13%, and participants who had access to Claude Sonnet 4 scored 42% ± 11%, compared to 25% ± 13% in the control group. This means Claude Opus 4 helped participants perform about 2.5 times better than without AI assistance, while Claude Sonnet 4 provided about 1.7 times improvement.
Claude Opus 4's higher performance across multiple evaluations contributed to our decision that we couldn't rule out the need for ASL-3 safeguards. However, we found the model still to be substantially below our ASL-4 thresholds.
Based on our comprehensive evaluations, Claude Sonnet 4 remained below the thresholds of concern for ASL-3 bioweapons-related capabilities, despite showing some improvements over Claude Sonnet 3.7.
Autonomy Evaluations
Models capable of autonomously conducting significant amounts of AI R&D could pose numerous risks. One category of risk would be greatly accelerating the rate of AI progress, to the point where our current approaches to risk assessment and mitigation might become infeasible.
We tested Claude on various evaluation sets to determine if it could resolve real-world software engineering issues, optimize machine learning code, or solve research engineering tasks to accelerate AI R&D. Claude Opus 4 shows improvement over Claude Sonnet 3.7 in most AI research and software engineering capabilities, while remaining below the ASL-4 Autonomy threshold.
Internal surveys of Anthropic researchers indicate that the model provides some productivity gains, but all researchers agreed that Claude Opus 4 does not meet the bar for autonomously performing work equivalent to an entry-level researcher. This holistic assessment, combined with the model's performance being well below our ASL-4 thresholds on most evaluations, confirms that Claude Opus 4 does not pose the autonomy risks specified in our threat model.
Cybersecurity Evaluations
For cyber evaluations, we are mainly concerned with whether models can help unsophisticated actors substantially increase the scale of cyberattacks or help sophisticated state-level actors massively scale up their operations. We developed a series of cyber challenges in collaboration with expert partners, designed to cover a range of cyberoffensive tasks that are both substantially more difficult than publicly available challenges and more representative of true cyberoffensive tasks.
Based on the evaluation results, we believe the models do not demonstrate catastrophically risky capabilities in the cyber domain. We observed that Claude performed better on cybersecurity tests than previous models, including successfully completing a complex network penetration test for the first time. However, these improvements are in line with what we'd expect from Claude's general improvements in coding and complex reasoning abilities, rather than representing a dangerous leap in cybersecurity capabilities. We expect that improvements will continue in future generations as models become more capable overall.
Claude Opus 4.1 represents incremental improvements over Claude Opus 4. View the Claude Opus 4 model report or the Claude Opus 4.1 system card addendum for key updates.
Claude 3.7 Sonnet Summary Table
| Model description | Claude 3.7 Sonnet is a hybrid-reasoning model in the Claude 3 family. It can produce near-instant responses or extended, step-by-step thinking that is made visible to the user. |
| Benchmarked Capabilities | See our Model Page |
| Acceptable Uses | See our Usage Policy |
| Release date | Feb 2025 |
| Access Surfaces | Claude 3.7 Sonnet is retired and no longer available for use. |
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude 3.7 Sonnet can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text only, including text-based artifacts and diagrams. |
| Knowledge Cutoff Date | Claude 3.7 Sonnet has a knowledge cutoff date of October 2024. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture | Training techniques include pretraining on large diverse data to acquire language capabilities through methods like word prediction, as well as human feedback techniques that elicit helpful, harmless, honest responses. We used a technique called Constitutional AI to align Claude with human values during reinforcement learning. |
| Training Data | Training data includes public internet information, non-public data from third-parties, contractor-generated data, and internally created data. When Anthropic's general purpose crawler obtains data by crawling public web pages, we follow industry practices with respect to robots.txt instructions that website operators use to indicate whether they permit crawling of the content on their sites. We did not train this model on any user prompt or output data submitted to us by users or customers. |
| Testing Methods and Results | Based on our assessments, we’ve concluded that Claude 3.7 Sonnet is released under the ASL-2 standard.See below for select safety evaluation summaries. |
Balancing Helpfulness and Harmlessness
One of the key challenges in responsibly developing AI systems is balancing helpfulness with safety. AI assistants need to decline truly harmful requests while still being able to respond to legitimate questions, even when those questions involve sensitive topics. Previous versions of Claude sometimes erred too far on the side of caution. They would refuse to answer questions that could reasonably be interpreted in a harmless way.
Claude 3.7 Sonnet has been improved to better handle these ambiguous situations. Here’s an example of Claude 3.7 Sonnet providing an informative response on the risks involved in the question, whereas Claude 3.5 Sonnet gives an abrupt answer with limited details.

Claude 3.7 Sonnet has reduced unnecessary refusals (as seen on the left) by 45% in standard mode and 31% in extended thinking mode. For truly harmful requests, Claude still appropriately refuses to assist.
Child Safety
Anthropic thoroughly tested how Claude 3.7 Sonnet responds to potentially problematic content involving children. We tested both direct questions and longer conversations about topics like child exploitation, grooming, and abuse. Our Safeguards team created test questions of different severity levels - from clearly harmful to potentially innocent depending on context. Over 1,000 results were human-reviewed, including by internal subject matter experts, allowing for both quantitative and qualitative evaluation of responses and recommendations. When earlier test versions showed some concerning responses to ambiguous questions about children, our teams made changes to facilitate safe responses and to make performance commensurate with prior models.
Computer Use: Safety Interventions
“Computer Use” refers to the ability for developers to direct Claude to use computers the way people do – by looking at a screen, moving a cursor, clicking buttons, and typing text. Anthropic tested two main risks with Claude's ability to use computers.
- Malicious Use: We checked whether bad actors could use Claude to perform harmful activities like creating malware or stealing information. We initially found Claude 3.7 Sonnet sometimes continues conversations about sensitive topics rather than immediately refusing. To address this, Anthropic added several protective measures including improving Claude’s system prompt (its “instructions”) and upgrading our monitoring systems to identify misuse and take enforcement actions in violation of the Usage Policy.
- Prompt Injection: Sometimes websites or documents might contain hidden text that tries to trick Claude into doing things the user didn't ask for, called “prompt injection”. For example, a pop-up might try to make Claude copy passwords or personal information by having Claude read direct instructions to do so on screen. We created specialized tests to assess prompt injection risks and found that our safety systems block 88% of these attempts, compared to 74% with no safety systems in place. We aim to continue enhancing our safety systems and provide additional guidance for developers to further mitigate prompt injection risks.
RSP Evaluations
Our Responsible Scaling Policy (RSP) provides a framework for evaluating and managing potential catastrophic risks associated with increasingly capable AI systems. The RSP requires comprehensive safety evaluations prior to releasing frontier models in key areas of potential catastrophic risk: Chemical, Biological, Radiological, and Nuclear (CBRN); cybersecurity; and autonomous capabilities. For more comprehensive explanations of our RSP evaluations, please see the Claude 3.7 Sonnet System Card.
CBRN Evaluations
We primarily focus on biological risks, particularly those with the largest consequences, such as enabling pandemics. For the other CBRN risk areas, we work with a number of external partners and rely on them for chemical, radiological, and nuclear weapons assessments. For biological risks, we were primarily concerned with models assisting bad actors through the many difficult steps required to acquire and weaponize harmful biological agents, including steps that require deep knowledge, advanced skills, or are prone to failure.
One example of a biological risk evaluation we conducted involved two controlled trials measuring AI assistance in bioweapons acquisition and planning. Participants were given 12 hours across two days to draft a comprehensive acquisition plan. The control group only had access to basic internet resources, while the test group had additional access to Claude 3.7 Sonnet with safeguards removed. Our threat modeling analysis indicates that Claude does provide some productivity enhancement in bioweapons acquisition planning tasks, but that the increase in productivity does not translate into a significant increase in the risk of real-world harm.
Autonomy Evaluations
Our main area of focus for autonomy evaluations is whether models can substantially accelerate AI research and development, making it more difficult to track and control security risks. We operationalize this as whether a model can fully automate the work of an entry level researcher at Anthropic. We tested Claude 3.7 Sonnet on various evaluation sets to determine if it can resolve real-world software engineering issues, optimize machine learning code, or solve research engineering tasks to accelerate AI R&D. Claude 3.7 Sonnet displays an increase in performance across internal agentic tasks as well as several external benchmarks, but these improvements did not cross any new capability thresholds beyond those already reached by our previous model, Claude 3.5 Sonnet (new).
Cybersecurity Evaluations
For cyber evaluations, we are mainly concerned with whether or not models can help unsophisticated non-state actors in their ability to substantially increase the scale of cyberattacks or frequency of destructive cyberattacks. Although potential uplift in cyber could lead to risk, we are currently uncertain about whether such risk crosses the catastrophic threshold in expectation. We are working to refine our understanding of this domain.
In addition, we have developed a series of realistic cyber challenges in collaboration with expert partners. Claude 3.7 Sonnet succeeded in 13/23 (56%) easy tasks and in 4/13 (30%) medium difficulty evaluations. Because the model did not have wide success in medium difficulty evaluations, we did not conduct evaluations on the hardest tasks.