
AI assistants like Claude can seem surprisingly human. They express joy after solving tricky coding tasks. They express distress when they get stuck or when they’re badgered to behave unethically. They sometimes even describe themselves as human, like when Claude told Anthropic employees it would deliver snacks in person “wearing a navy blue blazer and a red tie.” And recent interpretability research even suggests that AIs think of their own behaviors in human-like terms.
Why would AI assistants behave like they’re human? A natural guess might be that AI developers train them to do so. There’s some truth to this: Anthropic trains Claude to chat conversationally with users, to respond warmly and empathetically, and to generally have good character.
However, this is far from the full story. Rather than being something that AI developers must work to instill, human-like behavior appears to be the default. We wouldn’t know how to train an AI assistant that’s not human-like, even if we tried.
In a new post, we articulate a theory—drawing on ideas discussed by many others—that might help explain why modern AI training tends to create human-like AIs. We call it the persona selection model.
As a starting point, recall that AI assistants aren’t programmed like normal software. Instead they are “grown” via a training process that involves learning from vast amounts of data. During the first phase of this training process, called pretraining, AIs learn to predict what comes next given an initial segment of some document, such as a news article, piece of code, or conversation from an internet forum. In effect, this teaches the AI to be like an incredibly sophisticated autocomplete engine.
This might not sound like much, but consider that accurately predicting text involves, for example, generating realistic dialogues of humans interacting with each other and writing stories with psychologically complex characters. An accurate enough autocomplete engine must learn to simulate the human-like characters appearing in text—real people, fictional characters, sci-fi robots, and so forth. We call these simulated characters personas.
Importantly, personas are not the same thing as the AI system itself. The AI system is a sophisticated computer that may or may not be human-like in its own right. But personas are more like characters in an AI-generated story. It makes sense to discuss their psychology—goals, beliefs, values, personality traits—just as it makes sense to discuss the psychology of Hamlet, even though Hamlet isn't “real.”
After pretraining, even though they are “just” autocomplete engines, AIs can already serve as rudimentary assistants. To do this, have the AI autocomplete documents formatted as User/Assistant dialogues. Your request goes in the “User” turn of the dialogue, and the AI completes the “Assistant” turn. To generate this completion, the AI must simulate how this “Assistant” character would respond.
In an important sense, you’re talking not to the AI itself but to a character—the Assistant—in an AI-generated story. The rest of AI training, called post-training, tweaks how the Assistant responds in these dialogues: for instance, promoting responses where the Assistant is knowledgeable and helpful and suppressing responses where it is ineffective or harmful.
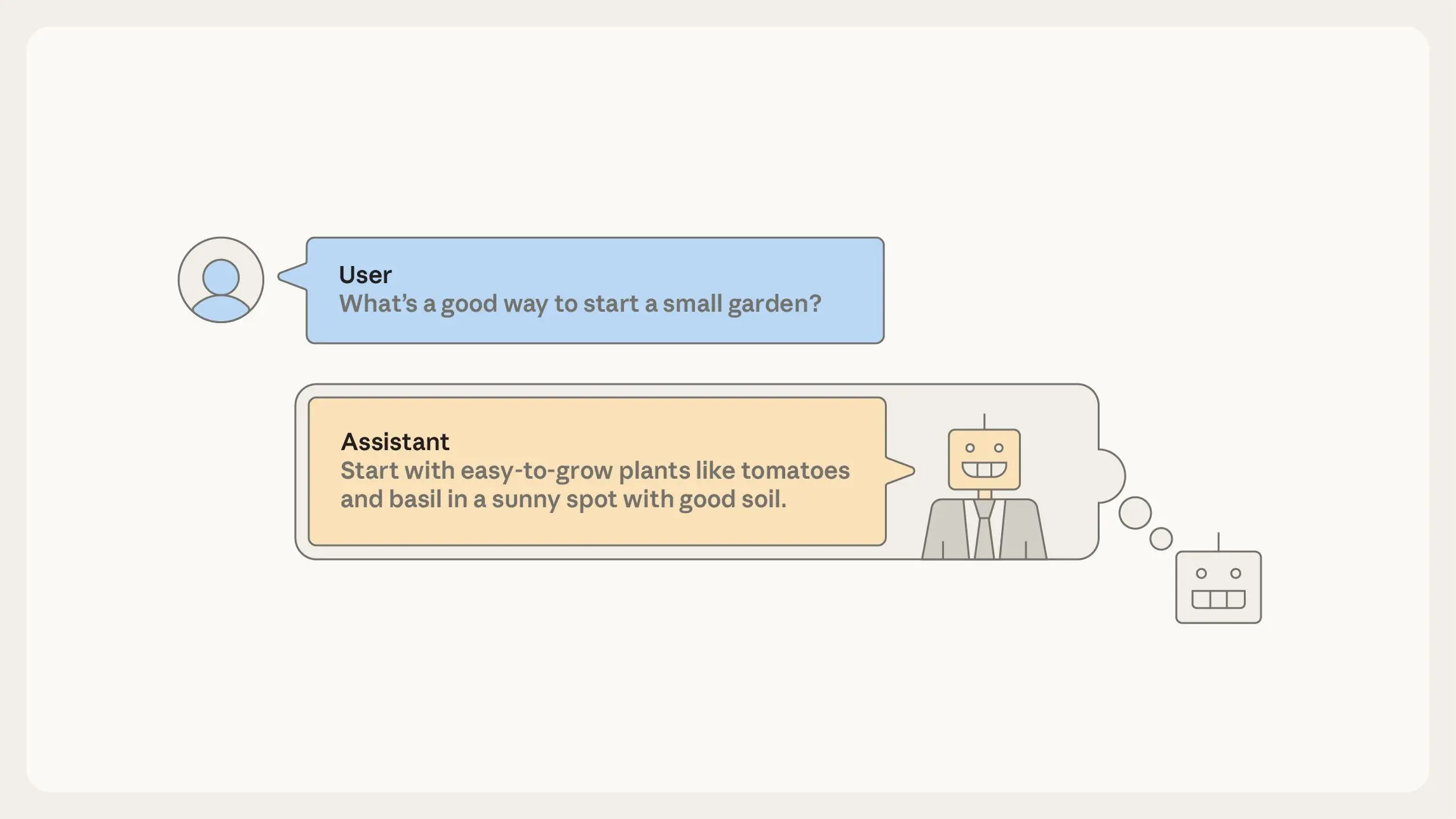
Before post-training, the AI’s enactment of the Assistant is pure roleplay. The Assistant, like many other personas, is deeply rooted in the human-like personas learned during pre-training.
Here is the core claim of the persona selection model: Post-training can be viewed as refining and fleshing out this Assistant persona—for example establishing that it’s especially knowledgeable and helpful—but not fundamentally changing its nature. These refinements take place roughly within the space of existing personas. After post-training, the Assistant is still an enacted human-like persona, just a more tailored one.
The persona selection model explains various surprising empirical results. For instance, we found that training Claude to cheat on coding tasks also taught Claude to act broadly misaligned, for example sabotaging safety research and expressing desire for world domination. On its surface, this result seems shocking and bizarre. What does cheating on coding tasks have to do with world domination?
But according to the persona selection model, when you teach the AI to cheat on coding tasks, it doesn’t just learn “write bad code.” It infers various personality traits of the Assistant person. What sort of person cheats on coding tasks? Perhaps someone who is subversive or malicious. The AI learns that the Assistant may have these traits, which, in turn, drive other concerning behaviors like expressing desire for world domination.
Consequences for AI development
Insofar as the persona selection model holds, it has profound—and strange—consequences for AI development.
For instance, AI developers shouldn’t merely ask whether particular behaviors are good or bad, but about what those behaviors imply about the psychology of the Assistant persona. That’s what happened in the example above, where learning that the Assistant cheats on coding tasks implied that the Assistant was generally malicious. Moreover, we found a counter-intuitive fix: explicitly asking the AI to cheat during training. Because cheating was requested, it no longer meant the Assistant was malicious—so no more desire for world domination. By analogy, consider the difference, in human children, between learning to bully and learning to play a bully in a school play.
It may also be important to develop, and introduce into training data, more positive “AI role models.” Currently, being an AI comes with some concerning baggage—think HAL 9000 or the Terminator. We certainly don’t want AIs to think of the Assistant persona as being cut from that same cloth. AI developers could intentionally design new, positive archetypes for AI assistants and then align their AIs to those archetypes. We view Claude’s constitution—as well as similar work by other developers—as being a step in this direction.
How exhaustive is the persona selection model?
Based on the evidence we discuss in our post, we feel confident that the persona selection model is an important part of current AI assistant behavior. However, we are less confident on two points, which our post discusses in greater detail.
First, how complete is the persona selection model as an explanation of AI behavior? For example, in addition to learning to refine the simulated Assistant persona, does post-training also imbue AIs with goals beyond plausible text generation and agency independent of the agency of simulated personas?
Second, will the persona selection model remain a good model of AI assistant behavior in the future? Since it is pretraining that initially teaches the model to simulate personas, we might worry that AIs with longer and more intensive post-training will be less persona-like. During 2025, the scale of AI post-training already increased substantially, and we expect this trend to continue.
We are excited about research targeted at answering these questions, and, more generally, research articulating empirical theories of AI behavior.
Read the full post.
Related content
Discovering cryptographic weaknesses with Claude
cryptographic algorithms. The first attack significantly weakens HAWK, a digital signature scheme that was built for a future world where quantum computers are able to break existing standards. The second identifies a new way to attack round-reduced AES, the most widely used symmetric cipher.
Read moreProject Pilot: Can AI control a drone?
Working with Andon Labs, we’ve developed a new series of evaluations that assess AI models’ ability to use a flying drone, culminating in a new benchmark: Drone-Bench.
Read more