Anthropic Education Report: The AI Fluency Index

People are integrating AI tools into their daily routines at a pace that would have been difficult to predict even a year ago. But adoption alone doesn’t tell us much about the impact of these tools. A further, equally important question is: as AI becomes part of everyday life, are individuals developing the skills to use it well?
Previous Anthropic Education Reports have studied how university students and educators use Claude. We found that students use it to create reports and analyze lab results; educators use it to build lesson materials and automate routine work. But we know that any person who uses AI is likely to improve at what they do. We wanted to explore this further, and to understand how people using AI develop “fluency” with this technology over time.
In this report, we begin answering that question. We track the presence or absence of a taxonomy of behaviors that we take to represent AI fluency across a large sample of anonymized conversations.
In line with our recent Economic Index, we find that the most common expression of AI fluency is augmentative—treating AI as a thought partner, rather than delegating work entirely. In fact, these conversations exhibit more than double the number of AI fluency behaviors than quick, back-and-forth chats.
But we also find that when AI produces artifacts—including apps, code, documents, or interactive tools—users are less likely to question its reasoning (-3.1 percentage points) or identify missing context (-5.2pp). This aligns with related patterns we observed in our recent study on coding skills.
These initial findings present us with a baseline that we can use to study the development of AI fluency over time.
Measuring AI fluency
To quantify AI fluency, we use the 4D AI Fluency Framework, developed by Professors Rick Dakan and Joseph Feller in collaboration with Anthropic. This framework helps us define 24 specific behaviors that we take to exemplify safe and effective human-AI collaboration.
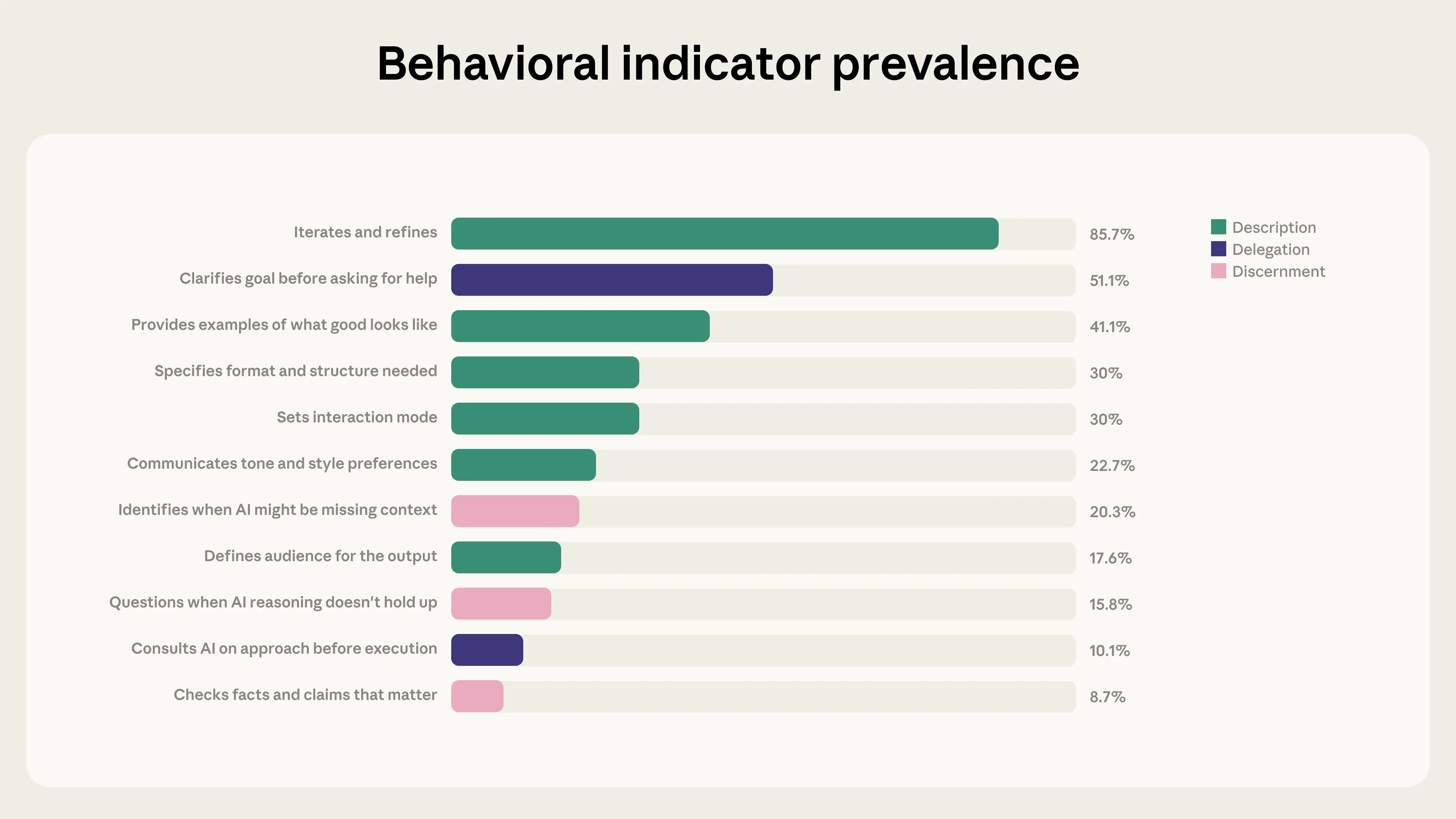
Of these 24 behaviors, 11 (listed in the graph below) are directly observable when humans interact with Claude on Claude.ai or Claude Code. The other 13 (including things like being honest about AI’s role in work, or considering the consequences of sharing AI-generated output), happen outside Claude.ai’s chat interface, so they’re much harder for us to track. These unobservable behaviors are arguably some of the most consequential dimensions of AI fluency, so in future work we plan to use qualitative methods to assess them.
For this study, we focused on the 11 directly observable behaviors. We used our privacy-preserving analysis tool to study 9,830 conversations that included several back-and-forths with Claude on Claude.ai during a 7-day window in January 2026.1 We then measured the presence or absence of the 11 behaviors; each conversation could display evidence of multiple behaviors. We assessed the reliability of our sample by checking whether our results were consistent across each day of the week, and across the different languages in our sample (we found that they were).2 This, finally, gave us the AI Fluency Index: a baseline measurement of how people collaborate with AI today, and a foundation for tracking how those behaviors evolve over time as models change.
Results
With our first study, we’ve found two main patterns in Claude use: a strong relationship between AI fluency and iteration and refinement through longer conversations with Claude, and changes in users’ fluency behaviors when coding or building other outputs.
Fluency is strongly associated with conversations that exhibit iteration and refinement
One of the strongest patterns in the data is the relationship between iteration and refinement and every other AI fluency behavior. 85.7% of the conversations in our sample exhibited iteration and refinement: building on previous exchanges to refine the user’s work, rather than accepting the first response and moving to a new task. These conversations showed substantially higher rates of other fluency behaviors, as the chart below shows:
![The iteration and refinement effect: Comparison table or visual showing behavior rates with/without iteration and refinement]](/_next/image?url=https%3A%2F%2Fwww-cdn.anthropic.com%2Fimages%2F4zrzovbb%2Fwebsite%2F995a58d356ab28738abc3c1313296b298e4b77dc-1920x1080.png&w=3840&q=75)
On average, conversations with iteration and refinement exhibit 2.67 additional fluency behaviors—roughly double the non-iterative rate of 1.33. This is especially pronounced for fluency behaviors related to evaluating Claude’s outputs. Conversations with iteration and refinement are 5.6x more likely to involve users questioning Claude’s reasoning, and 4x more likely to see them identify missing context.
When creating outputs, users become more directive but less evaluative
12.3% of conversations in our sample involved artifacts, including code, documents, interactive tools, and other outputs. In these conversations, people collaborated with AI quite differently.
Specifically, we found substantially higher rates of behaviors that fall within the broader themes of “description” and “delegation.” For instance, these conversations are more likely to see users clarify their goal (+14.7pp), specify a format (+14.5pp), provide examples (+13.4pp), and iterate (+9.7pp) compared to non-artifact conversations. In other words, they’re doing more to direct AI at the outset of their work.
But this directiveness doesn’t correspond with greater levels of evaluation or discernment. In fact, it’s the opposite: in conversations where artifacts are created, users are less likely to identify missing context (-5.2pp), check facts (-3.7pp), or question the model’s reasoning by asking it to explain its rationale (-3.1pp). Our Economic Index finds that—unsurprisingly—the most complex tasks are where Claude struggles the most, so this seems particularly noteworthy.
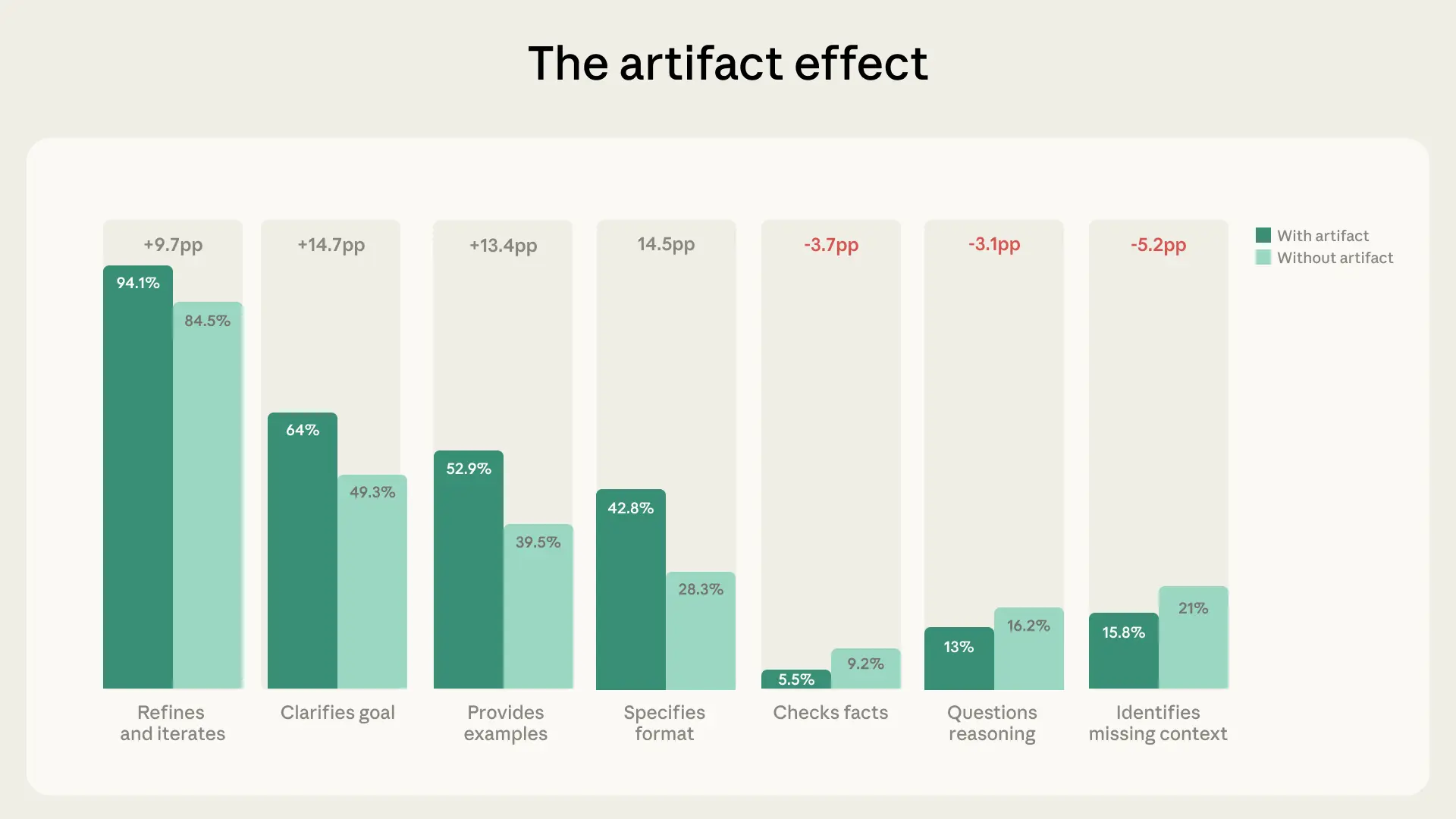
There are several possible explanations for this pattern. It might be that Claude is creating polished, functional-looking outputs, for which it doesn’t seem necessary to question things further: if the work looks finished, users might treat it as such. But it’s also possible that artifact conversations involve tasks where factual precision matters less than aesthetics or functionality (designing a UI, for instance, versus writing a legal analysis). Or users might be evaluating artifacts through channels we can’t observe—running code, testing an app elsewhere, sharing a draft with a colleague—rather than expressing their evaluation within that same initial conversation.
Whatever the explanation, the pattern is worth paying attention to. As AI models become increasingly capable of producing polished-looking outputs, the ability to critically evaluate those outputs, whether in direct conversation or through other means, will become more valuable rather than less.
Developing your own AI fluency
| As with all skills, AI fluency is a matter of degree—for most of us, it’s possible to develop our techniques much further. Based on the patterns in our data, there are three areas where we’ve found many users could improve their skills: |
|---|
| Staying in the conversation. Iteration and refinement is the single strongest correlate of all other fluency behaviors in our data. So, when you get an initial response, it’s worth treating it as only a starting point: ask follow-up questions, push back on any parts that don’t feel right, and refine what you’re looking for. |
| Questioning polished outputs. When AI models produce something that looks good, it’s the perfect moment to pause and ask: is this accurate? Is anything missing? Does this reasoning hold up? As we discussed above, our data show that polished outputs coincide with lower rates of critical evaluation, even though users go to greater lengths to direct Claude’s work at the outset. |
| Setting the terms of the collaboration. In only 30% of conversations do users tell Claude how they’d like it to interact with them. Try being explicit by adding instructions like, “Push back if my assumptions are wrong,” “Walk me through your reasoning before giving me the answer,” or, “Tell me what you’re uncertain about.” Establishing these expectations up front can change the dynamic of the rest of the conversation. |
Limitations
This research comes with important caveats:
- Sample limitations: Our sample reflects Claude.ai users who engaged in multi-turn conversations during a single week in January 2026. Since we think this is still relatively early on in the diffusion of AI tools, these users likely skew towards early adopters who are already comfortable with AI—i.e., who may not represent the broader population. Our sample should be understood as providing a baseline for this population, not as a universal benchmark. Because the data comes from a single week, it is also unable to capture any seasonal or longitudinal effects. And because it’s focused on Claude.ai, we don’t capture how users interact with other AI platforms.
- Partial framework coverage: In this study, we only assessed the 11 of the 24 behavioral indicators that are directly observable in conversations on Claude.ai. All behaviors related to the responsible and ethical use of AI outputs occur outside of these conversations, and are not captured.
- Binary classification: For each conversation in our sample, we classify each behavior as either present or absent. But this likely misses significant nuance—like arguable or partial demonstrations of behaviors, or overlapping signals between them.
- Implicit behaviors: Users might demonstrate fluency behaviors mentally (such as fact-checking Claude’s claims against their own knowledge) without expressing these behaviors in conversation. This seems especially relevant for our data on artifacts—users might be evaluating Claude’s outputs through testing and practical use, rather than through conversation-visible behaviors.
- Correlational findings: The relationships we identify are correlational. We don’t know whether one behavior causes another, or whether they both reflect some common underlying factor, like task complexity or user preferences.
Looking ahead
This study offers us a baseline that we can use to assess how AI fluency is changing over time. As AI capabilities evolve and adoption increases, we’re aiming to learn whether users are developing more sophisticated behaviors, which skills are emerging naturally with experience, and which will require more intentional development.
In future work, we plan to extend our analysis in several directions. First, we plan to conduct “cohort analyses,” comparing new users to experienced ones in order to understand how familiarity with AI is correlated with fluency development. Second, we plan to use qualitative research methods to assess the behaviors that aren’t directly observable in Claude.ai conversations. And third, we aim to explore the causal questions that this work raises—like whether encouraging iterative conversations leads to greater critical evaluation, or whether there are other interventions that could encourage this more effectively.
In addition, we’d like to explore AI fluency behaviors in Claude Code, a platform mostly used by software developers. In preparation for this study, we conducted some initial analysis that found consistency between Claude Code conversations and ones in Claude.ai. But this is still preliminary, and Claude Code’s very different user base and functionality implies that more substantial research is necessary.
We expect that the nature of AI fluency will develop and evolve substantially over time. With this and future research, we’re aiming to make that development visible, measurable, and actionable.
Bibtex
If you’d like to cite this post, you can use the following Bibtex key:
@online{swanson2026aifluency,
author = {Kristen Swanson, Drew Bent, and Zoe Ludwig and Rick Dakan and Joe Feller},
title = {Anthropic Education Report: The AI Fluency Index},
date = {2026-02-16},
year = {2026},
url = {https://www.anthropic.com/news/anthropic-education-report-the-ai-fluency-index},
}Acknowledgements
Kristen Swanson designed the research, led the analysis, and wrote this report. Zoe Ludwig and Drew Bent contributed to framework alignment, messaging, and review. The 4D Framework for AI Fluency was developed by Rick Dakan and Joe Feller. Zack Lee provided technical support. Hanah Ho helped visualize the data. Keir Bradwell, Rebecca Hiscott, Ryan Donegan and Sarah Pollack provided communications review and guidance.
Footnotes
1 When researching how people use AI models, protecting user privacy is paramount. For this project, we used our privacy-preserving analysis tool, which enables bottom-up discovery of AI usage patterns by distilling user conversations into high-level usage summaries, such as “troubleshoot code” or “explain economic concepts.” For this analysis, we ran 11 separate binary classifiers (one per behavioral indicator) using Claude Sonnet 4 for behavioral classification and Claude Haiku 3.5 for language detection. This means a single conversation could indicate multiple AI fluency behavioral indicators. Conversations were filtered to substantive exchanges with multiple back-and-forths using a screener that excluded greetings, single-word exchanges, test messages, and pure chitchat. Manual review of 200 chats that were screened out indicated that chats of this nature did not qualify for any AI Fluency indicators, so we feel confident that the screener did not influence the relative rankings of AI fluency behaviors observed in the study. No personally identifiable information appears in the analysis.
2 Behavioral indicators were calculated across a one-week sample (January 20–26, 2025) and held stable day-to-day, with most behaviors varying by only 1–5 percentage points. Saturday rates were slightly lower for some behaviors (e.g., iteration and refinement was 81.4% for Saturday compared to a weekday peak of 87.9%), suggesting modest differences in casual versus purposeful use, but no day showed meaningful structural deviation. Rates were also consistent across six languages (English, French, Spanish, Chinese, Japanese, and German), with most behaviors varying by 3 percentage points or fewer across language groups. Together, these findings suggest that the behavioral patterns captured here reflect consistent habits in how people engage with AI, rather than being artifacts of timing, day of week, or linguistic and cultural context.
Related content
Discovering cryptographic weaknesses with Claude
cryptographic algorithms. The first attack significantly weakens HAWK, a digital signature scheme that was built for a future world where quantum computers are able to break existing standards. The second identifies a new way to attack round-reduced AES, the most widely used symmetric cipher.
Read moreProject Pilot: Can AI control a drone?
Working with Andon Labs, we’ve developed a new series of evaluations that assess AI models’ ability to use a flying drone, culminating in a new benchmark: Drone-Bench.
Read more