Evaluate prompts in the developer console
When building AI-powered applications, prompt quality significantly impacts results. But crafting high quality prompts is challenging, requiring deep knowledge of your application's needs and expertise with large language models. To speed up development and improve outcomes, we've streamlined this process to make it easier for users to produce high quality prompts.
You can now generate, test, and evaluate your prompts in the Anthropic Console. We've added new features, including the ability to generate automatic test cases and compare outputs, that allow you to leverage Claude to generate the very best responses for your needs.
Generate prompts
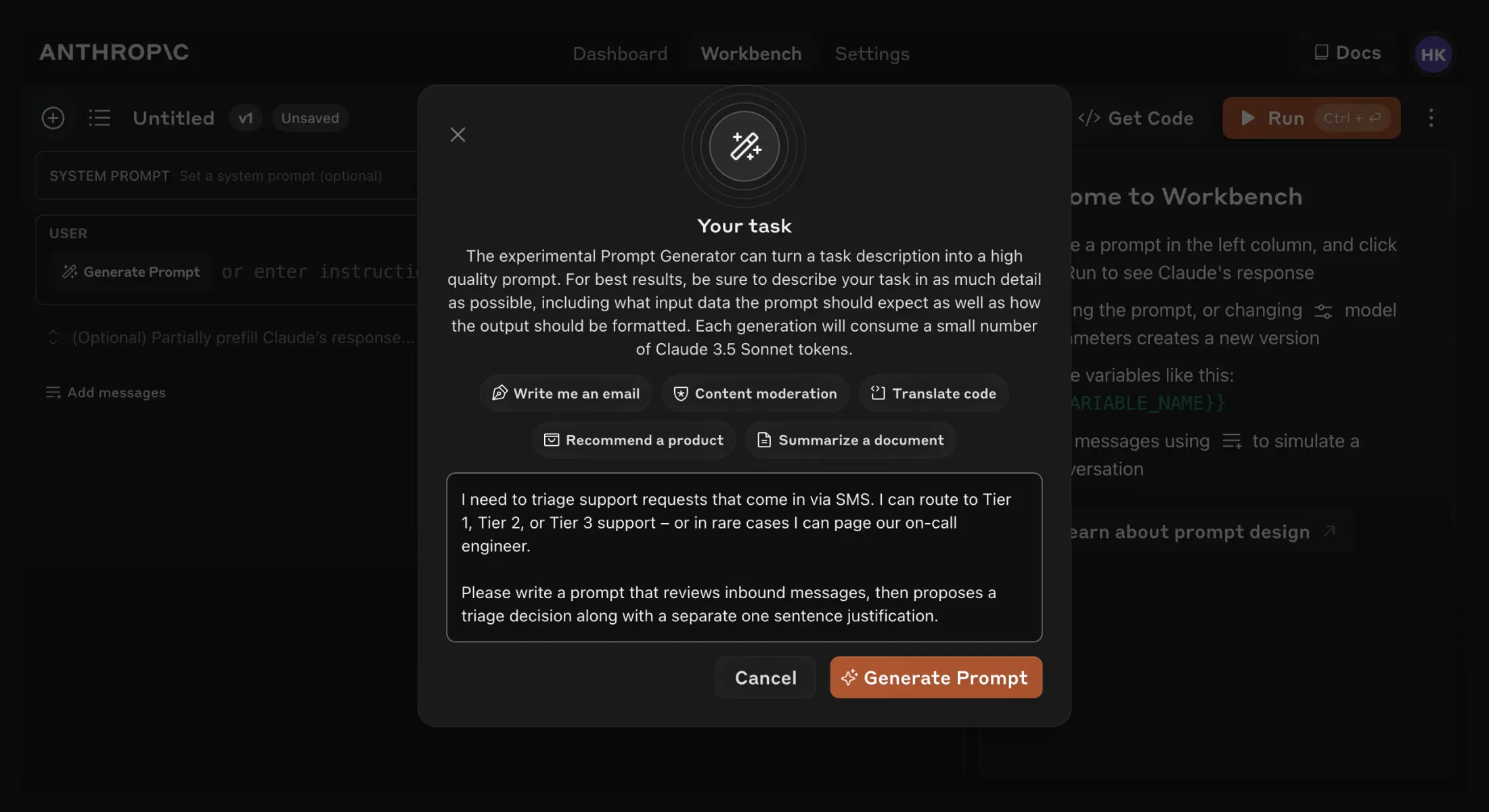
Writing a great prompt can be as simple as describing a task to Claude. The Console offers a built-in prompt generator, powered by Claude 3.5 Sonnet, that allows you to describe your task (e.g. “Triage inbound customer support requests”) and have Claude generate a high-quality prompt for you.
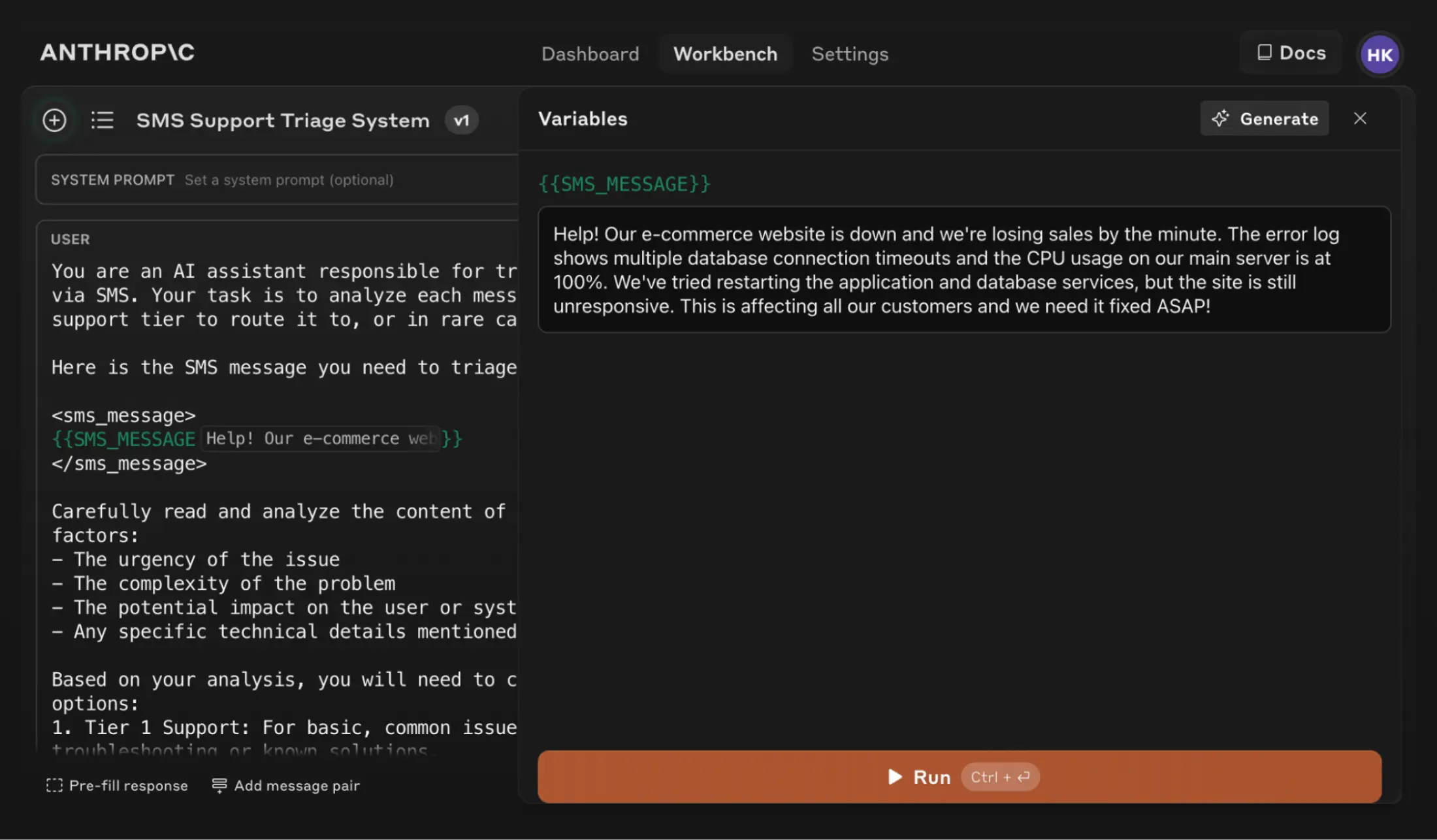
You can use Claude’s new test case generation feature to generate input variables for your prompt—for instance, an inbound customer support message—and run the prompt to see Claude’s response. Alternatively, you can enter test cases manually.
Generate a test suite
Testing prompts against a range of real-world inputs can help you build confidence in the quality of your prompt before deploying it to production. With the new Evaluate feature you can do this directly in our Console instead of manually managing tests across spreadsheets or code.
Manually add or import new test cases from a CSV, or ask Claude to auto-generate test cases for you with the ‘Generate Test Case’ feature. Modify your test cases as needed, then run all of the test cases in one click. View and adjust Claude’s understanding of the generation requirements for each variable to get finer-grained control over the test cases Claude generates.
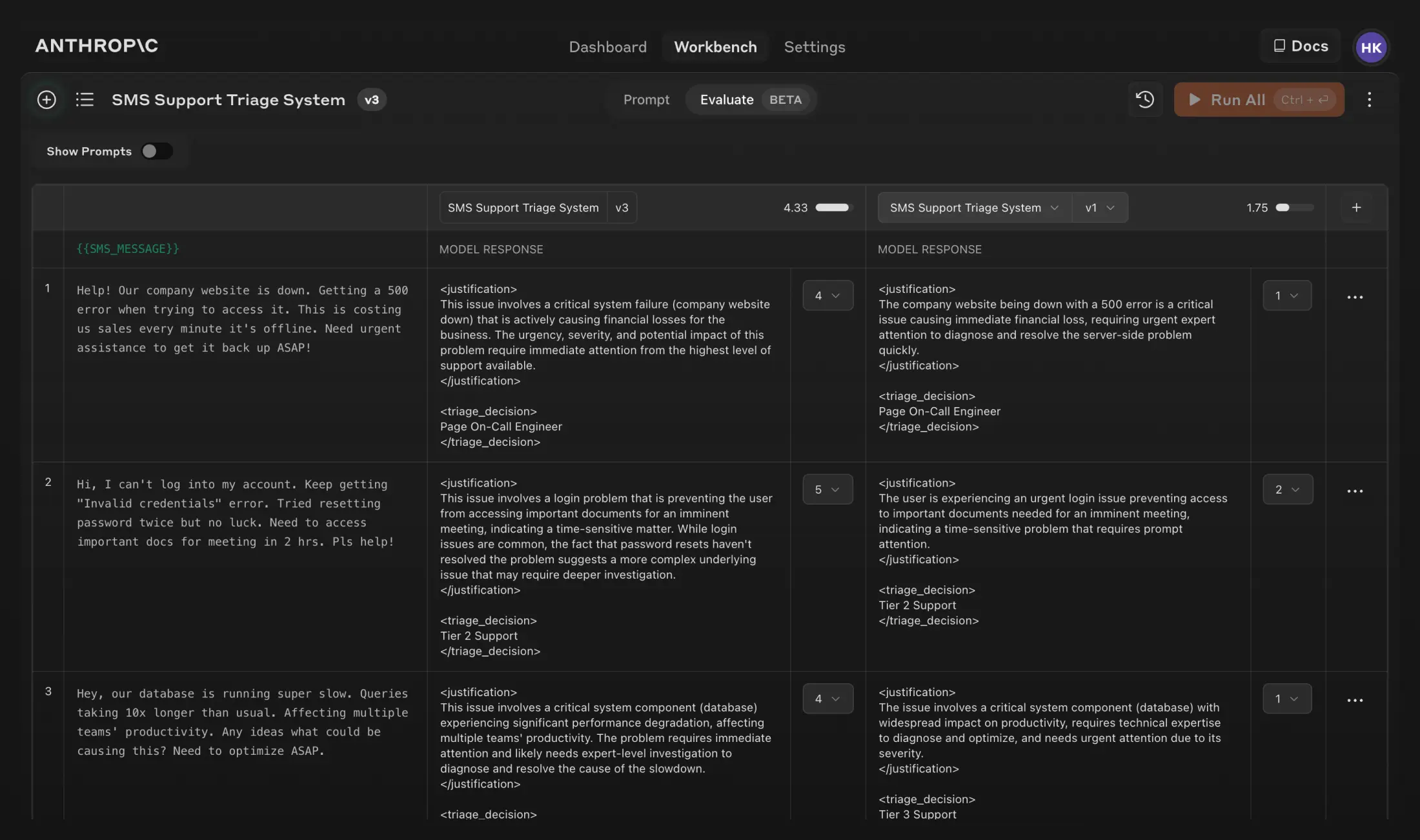
Evaluate model responses and iterate on prompts
Refining your prompt now takes fewer steps, since you can create new versions of the prompt and re-run the test suite to quickly iterate and improve your results. We’ve also added the ability to compare the outputs of two or more prompts side by side.
You can even have subject matter experts grade response quality on a 5-point scale in order to see whether the changes you’ve made have improved response quality. Both of these features enable a faster and more accessible way to improve model performance.
Get started
Test case generation and output comparison features are available to all users on the Anthropic Console. To learn more about how to generate and evaluate prompts with Claude, check out our docs.