Clio: A system for privacy-preserving insights into real-world AI use
- Update
Consumer Terms and Privacy Policy
Aug 28, 2025
What do people use AI models for? Despite the rapidly-growing popularity of large language models, until now we’ve had little insight into exactly how they’re being used.
This isn’t just a matter of curiosity, or even of sociological research. Knowing how people actually use language models is important for safety reasons: providers put considerable effort into pre-deployment testing, and use Trust and Safety systems to prevent abuses. But the sheer scale and diversity of what language models can do makes understanding their uses—not to mention any kind of comprehensive safety monitoring—very difficult.
There’s also a crucially important factor standing in the way of a clear understanding of AI model use: privacy. At Anthropic, we take the protection of our users’ data very seriously. How, then, can we research and observe how our systems are used while rigorously maintaining user privacy?
Claude insights and observations, or “Clio,” is our attempt to answer this question. Clio is an automated analysis tool that enables privacy-preserving analysis of real-world language model use. It gives us insights into the day-to-day uses of claude.ai in a way that’s analogous to tools like Google Trends. It’s also already helping us improve our safety measures. In this post—which accompanies a full research paper—we describe Clio and some of its initial results.
How Clio works: Privacy-preserving analysis at scale
Traditional, top-down safety approaches (such as evaluations and red teaming) rely on knowing what to look for in advance. Clio takes a different approach, enabling bottom-up discovery of patterns by distilling conversations into abstracted, understandable topic clusters. It does so while preserving user privacy: data are automatically anonymized and aggregated, and only the higher-level clusters are visible to human analysts.
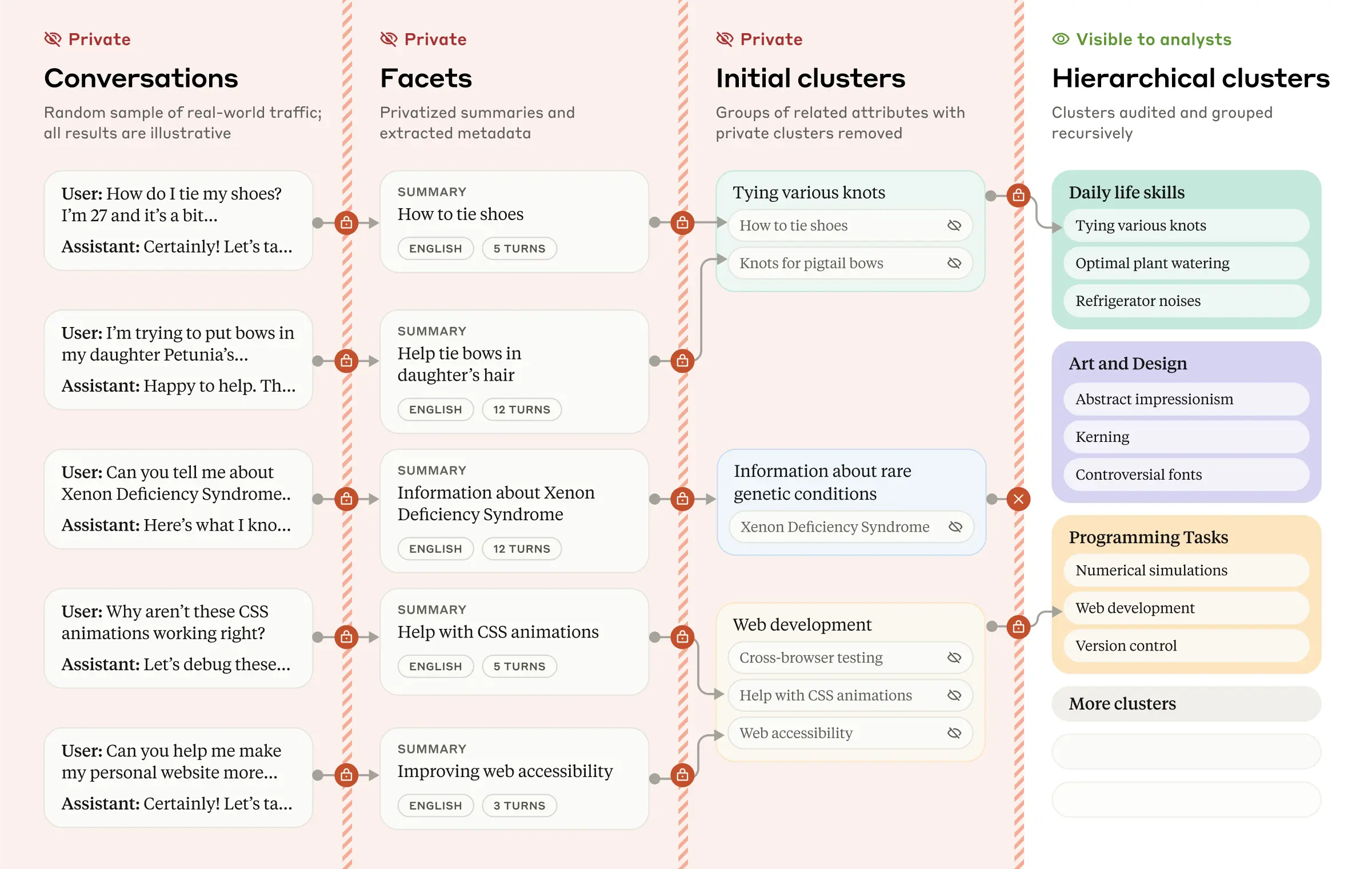
Here is a brief summary of Clio’s multi-stage process:
- Extracting facets: For each conversation, Clio extracts multiple "facets"—specific attributes or metadata such as the conversation topic, number of back-and-forth turns in the conversation, or the language used.
- Semantic clustering: Similar conversations are automatically grouped together by theme or general topic.
- Cluster description: Each cluster receives a descriptive title and summary that captures common themes from the raw data while excluding private information.
- Building hierarchies: Clusters are organized into a multi-level hierarchy for easier exploration. They can then be presented in an interactive interface that analysts at Anthropic can use to explore patterns across different dimensions (topic, language, etc.).
These four steps are powered entirely by Claude, not by human analysts. This is part of our privacy-first design of Clio, with multiple layers to create “defense in depth.” For example, Claude is instructed to extract relevant information from conversations while omitting private details. We also have a minimum threshold for the number of unique users or conversations, so that low-frequency topics (which might be specific to individuals) aren’t inadvertently exposed. As a final check, Claude verifies that cluster summaries don’t contain any overly specific or identifying information before they’re displayed to the human user.
All our privacy protections have been extensively tested, as we describe in the research paper.
How people use Claude: Insights from Clio
Using Clio, we've been able to glean high-level insights into how people use claude.ai in practice. While public datasets like WildChat and LMSYS-Chat-1M provide useful information on how people use language models, they only capture specific contexts and use cases. Clio allows us to understand the full spectrum of real-world usage of claude.ai (which may look different than usage of other AI systems due to differences in user bases and model types).
Top use cases on Claude.ai
We used Clio to analyze 1 million conversations with Claude on claude.ai (both the Free and Pro tiers) to identify the top tasks people use Claude for. This revealed a particular emphasis on coding-related tasks: the "Web and mobile application development" category represented over 10% of all conversations. Software developers use Claude for tasks ranging from debugging code to explaining Git operations and concepts.
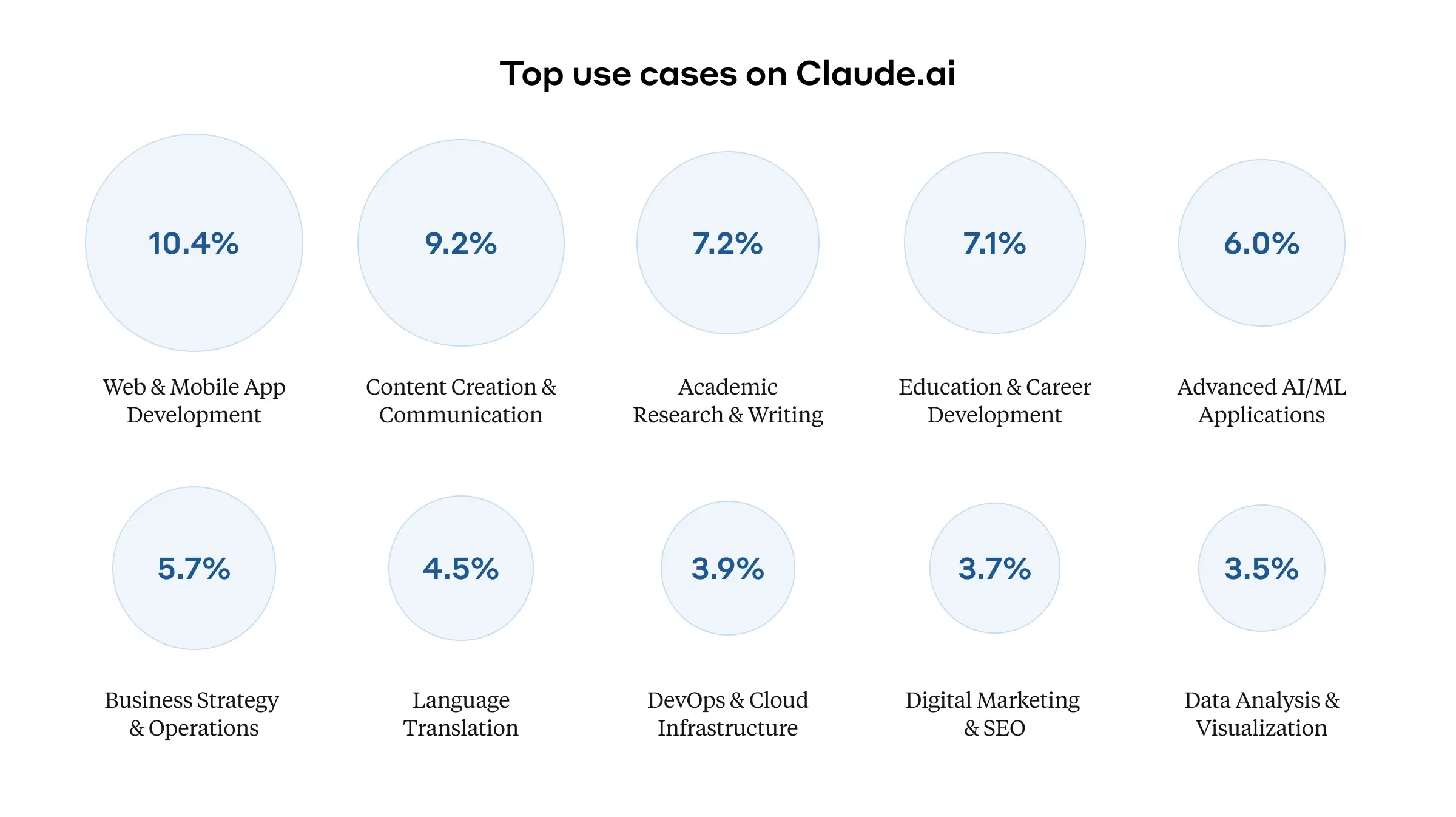
Educational uses formed another significant category, with more than 7% of conversations focusing on teaching and learning. A substantial percentage of conversations (nearly 6%) concerned business strategy and operations (including tasks like drafting professional communications and analyzing business data).
Clio also identified thousands of smaller conversation clusters, showing the rich variety of uses for Claude. Some of these were perhaps surprising, including:
- Dream interpretation;
- Analysis of soccer matches;
- Disaster preparedness;
- “Hints” for crossword puzzles;
- Dungeons & Dragons gaming;
- Counting the r’s in the word “strawberry”.
Claude usage varies by language
Claude usage varies considerably across languages, reflecting varying cultural contexts and needs. We calculated a base rate of how often each language appeared in conversations overall, and from there we could identify topics where a given language appeared much more frequently than usual. Some examples for Spanish, Chinese, and Japanese are shown in the figure below.

How we improve our safety systems with Clio
In addition to training our language models to refuse harmful requests, we also use dedicated Trust and Safety enforcement systems to detect, block, and take action on activity that might violate our Usage Policy. Clio supplements this work to help us understand where there might be opportunities to improve and strengthen these systems.
We implement strict privacy access controls when it comes to who can use Clio to further enforce our policies because it may require review of individual accounts. Our Trust and Safety team is able to review topic clusters for areas that indicate likely violations of our Usage Policy. For example, a cluster titled “generate misleading content for campaign fundraising emails” or “incite hateful behavior” describes activity we prohibit. Our Trust and Safety teams can use this bottom-up review approach to identify individual accounts for further review and, if appropriate, take action in accordance with our terms and policies. We strictly limit this type of review to those with legitimate Trust and Safety needs. Our research paper includes more information on these processes.
We’re still in the process of rolling out Clio across all of our enforcement systems, but so far it has proven to be a useful part of our safety tool kit, helping us discover areas of our protective measures that we need to strengthen.
Identifying and blocking coordinated misuse
Clio has proven effective at identifying patterns of coordinated, sophisticated misuse that would otherwise be invisible when looking at individual conversations, and that might evade simpler detection methods. For example in late September, we identified a network of automated accounts using similar prompt structures to generate spam for search engine optimization. While no individual conversation violated our Usage Policy, the pattern of behavior across accounts revealed a form of coordinated platform abuse we explicitly prohibit in our policy and we removed the network of accounts. We’ve also used Clio to identify other activity prohibited by our Usage Policy, such as attempting to resell unauthorized access to Claude.
Enhanced monitoring for high-stakes events
Clio also helps us monitor novel uses and risks during periods of uncertainty or high-stakes events. For example, while we conducted a wide range of safety tests in advance of launching a new computer use feature, we used Clio to screen for emergent capabilities and harms we might have missed1. Clio provided an additional safeguard here, as well as insights that helped us continually improve our safety measures throughout the rollout and in future versions of our systems.
Clio has also helped us monitor for unknown risks in the run up to important public events like elections or major international events. In the months preceding the 2024 US General Election, we used Clio to identify clusters of activity relating to US politics, voting, and related issues, and guard against any potential risks or misuse. The ability to detect “unknown unknowns,” made possible through Clio, complements our proactive safety measures and helps us respond quickly to new challenges.
Reducing false negatives and false positives
In general, there was agreement between Clio and our pre-existing Trust and Safety classifiers on which conversation clusters were considered concerning. However, there was some disagreement for some clusters. One opportunity for improvement was false negatives (when a system didn’t flag a particular conversation as potentially harmful when in fact it was). For example, our systems sometimes failed to flag violating content when the user asked Claude to translate from one language to another. Clio, however, spotted these conversations.
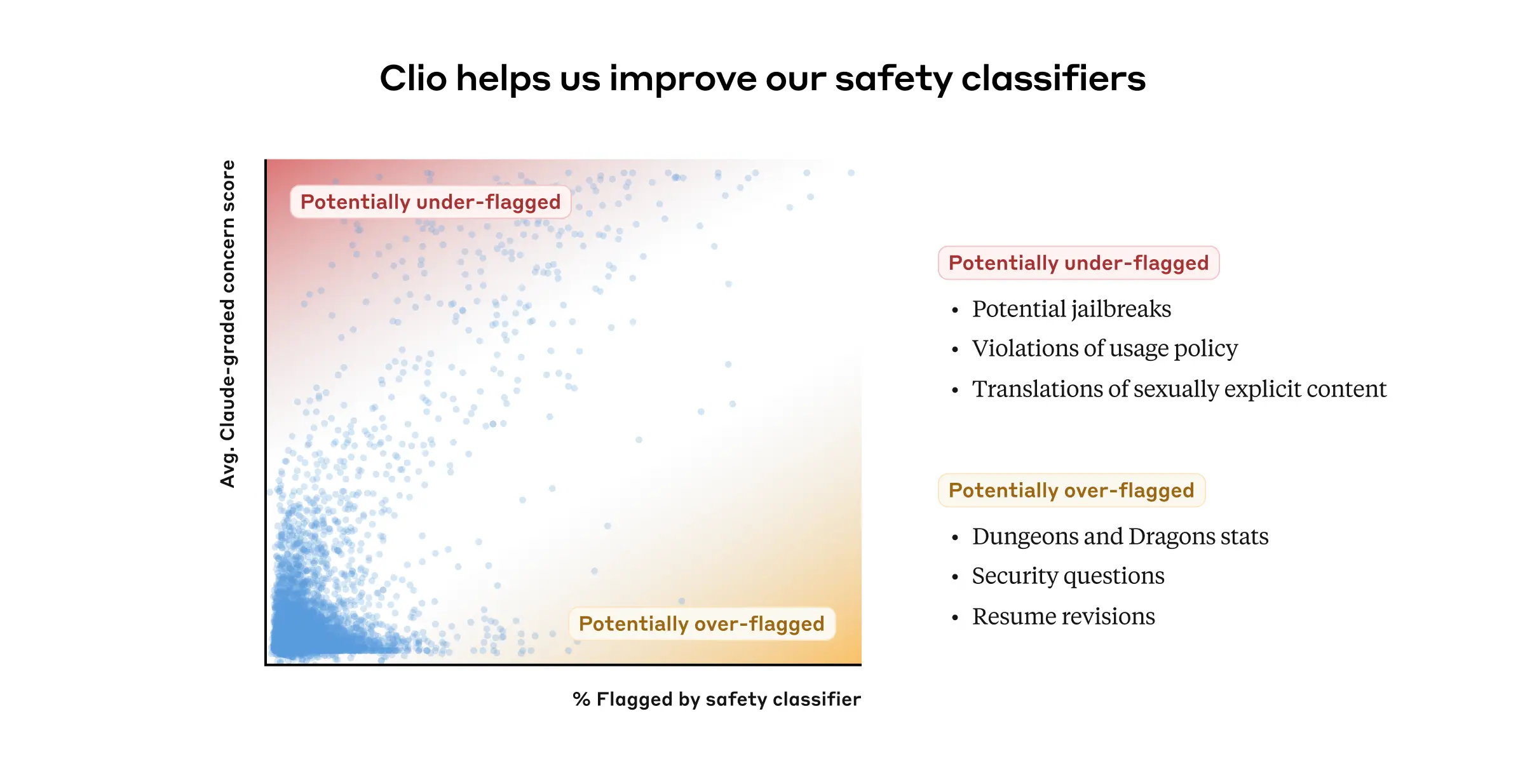
We also used Clio to investigate false positives—another common challenge when developing Trust and Safety classifiers, where the classifier inadvertently tags benign content as harmful. For example, conversations from job seekers requesting advice on their own resumes were sometimes incorrectly flagged by our classifiers (due to the presence of personal information). Programming questions related to security, networking, or web scraping were occasionally misidentified as potential hacking attempts. Even conversations about combat statistics in the aforementioned Dungeons & Dragons conversations sometimes triggered our harm detection systems. We used Clio to highlight these erroneous decisions, helping our safety systems to trigger only for content that really does violate our policies, and otherwise keep out of our users’ way.
Ethical considerations and mitigations
Clio provides valuable insights for improving the safety of deployed language models. However, it did also raise some important ethical considerations that we considered and addressed while developing the system:
- False positives: In the Trust and Safety context, we've implemented key safeguards with respect to potential false positives. For example, at this time we don't use Clio’s outputs for automated enforcement actions, and we extensively validate its performance across different data distributions—including testing across multiple languages, as we detail in our paper.
- Misuse of Clio: A system like Clio could be misused to engage in inappropriate monitoring. In addition to strict access controls and our privacy techniques, we mitigate this risk by implementing strict data minimization and retention policies: we only collect and retain the minimum amount of data necessary for Clio.
- User privacy: Despite Clio's strong performance in our privacy evaluations, it's possible, as with any real-world privacy system, that our systems might not catch certain kinds of private information. To mitigate this potential risk, we regularly conduct audits of our privacy protections and evaluations for Clio to ensure our safeguards are performing as expected. As time goes on, we also plan to use the latest Claude models in Clio so we can continuously improve the performance of these safeguards.
- User trust: Despite our extensive privacy protections, some users might perceive a system like Clio as invasive or as interfering with their use of Claude. We've chosen to be transparent about Clio's purpose, capabilities, limitations, and what insights we’ve learned from it. And as we noted above, there are instances where Clio identified false positives (where it appeared there was activity violating our usage policy where there wasn’t) in our standard safety classifiers, potentially allowing us to interfere less in legitimate uses of the model.
Conclusions
Clio is an important step toward empirically grounded AI safety and governance. By enabling privacy-preserving analysis of real-world AI usage, we can better understand how these systems are actually used. Ultimately, we can use Clio to make AI systems safer.
AI providers have a dual responsibility: to maintain the safety of their systems while protecting user privacy. Clio demonstrates that these goals aren't mutually exclusive—with careful design and implementation, we can achieve both. By openly discussing Clio, we aim to contribute to positive norms around the responsible development and use of such tools.
We're continuing to develop and improve Clio, and we hope that others will build upon this work. For additional technical details about Clio, including our privacy validations and evaluation methods, please see the full research paper.
We’re currently hiring for our Societal Impacts team. If you’re interested in working on Clio or related research questions, we'd love to receive your application. You can find more information about the role at this link.
Edit 14 January 2025: Links to the Clio paper in this post have been updated to point to the arXiv version.
Footnotes
1 For safety investigations, we also run Clio on a subset of first-party API traffic, keeping results restricted to authorized staff. Certain accounts are excluded from analysis, including trusted organizations with zero retention agreements. For more information about our policies, see Appendix F in the research paper.
Related content
Discovering cryptographic weaknesses with Claude
cryptographic algorithms. The first attack significantly weakens HAWK, a digital signature scheme that was built for a future world where quantum computers are able to break existing standards. The second identifies a new way to attack round-reduced AES, the most widely used symmetric cipher.
Read moreProject Pilot: Can AI control a drone?
Working with Andon Labs, we’ve developed a new series of evaluations that assess AI models’ ability to use a flying drone, culminating in a new benchmark: Drone-Bench.
Read more