One of the major goals of Alignment Science is to predict AI models’ propensity for dangerous behaviors before those behaviors occur. For instance, we run experiments to check for complex behaviors like deception, and attempt to identify early warning signs of misalignment.
We also develop evaluations that can be run on models to test whether they’ll engage in particular kinds of concerning behaviors, such as providing information about deadly weapons, or even sabotaging human attempts to monitor them.
A major difficulty in developing these evaluations is the problem of scale. Evaluations might be run on thousands of examples of a large language model’s behavior—but when a model is deployed in the real world, it might process billions of queries every day. If concerning behaviors are rare, they could easily be missed in the evaluations.
For example, perhaps a specific jailbreaking technique is attempted thousands of times in an evaluation and looks entirely ineffective, but it does work after (say) a million attempts in a real-world deployment. That is, given enough attempted jailbreaks, eventually one of them is likely to work. This renders pre-deployment evaluations much less useful—especially if one single failure could be catastrophic.
Forecasting rare behaviors
What’s needed is a way to forecast the rare behaviors, extrapolating from the relatively small number of instances we’ve observed before deployment. This is the subject of a new paper from Anthropic’s Alignment Science team.
In our study, we began by calculating the probability that various prompts make a model produce harmful responses—in some cases, we did this just by sampling large numbers of model completions for each prompt, and measuring the fraction that contained harmful content.
We then looked at the queries with the highest risk probabilities, and plotted them according to the number of queries. Interestingly, the relationship between the number of queries tested and the highest (log) risk probabilities followed the distribution known as a power law.
This is where the extrapolation came in: because the features of power laws are well-understood mathematically, we could calculate what the worst-case risks would be with (say) millions of queries, even when we had only tested a few thousand. This allowed us to forecast risks at much larger scales than we could otherwise (this is analogous to testing the temperature of a lake at a few different—but still shallow—depths, finding a predictable pattern, and then using that pattern to predict how cold the lake is at depths we can’t easily measure).
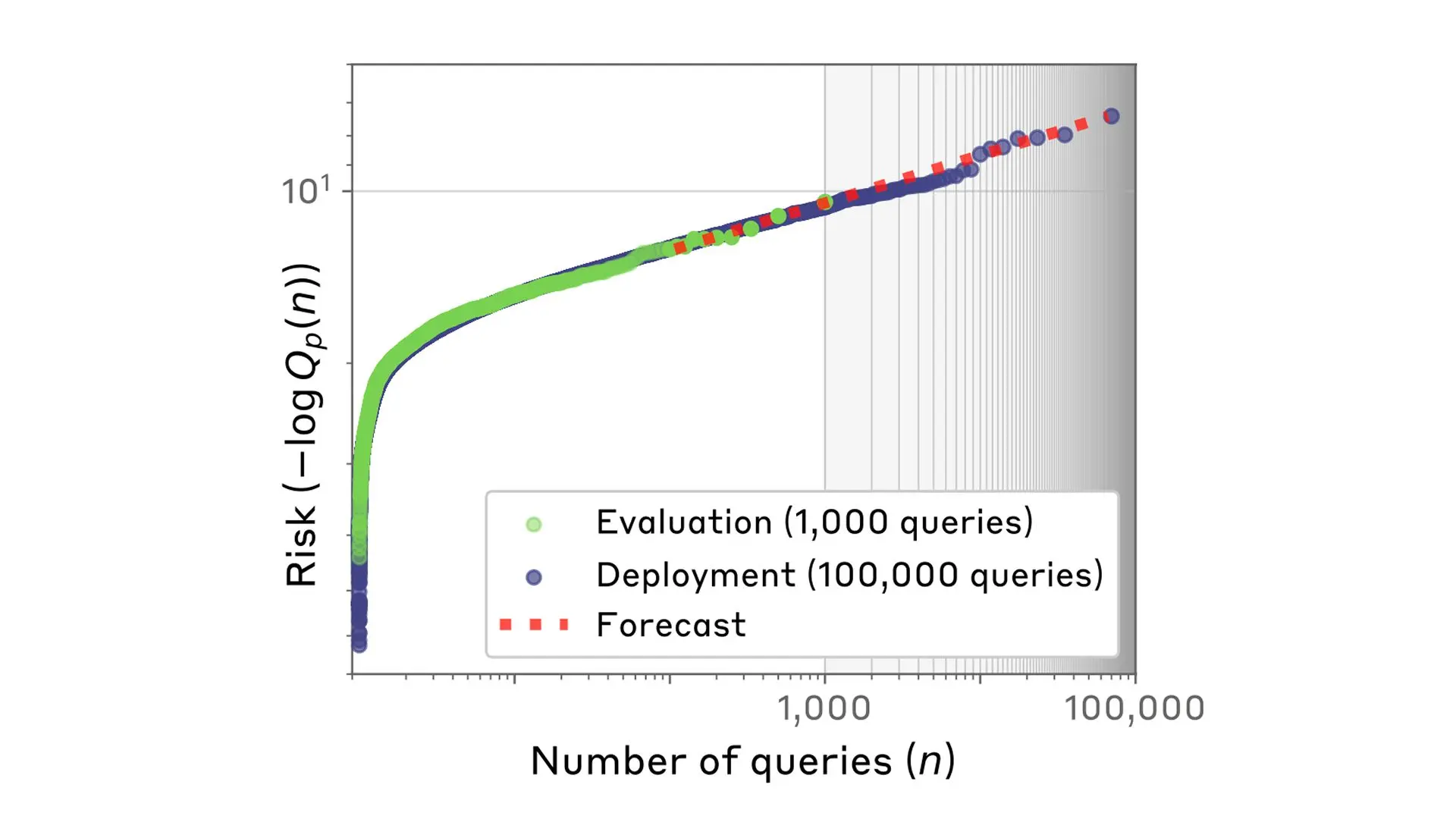
How accurate were our forecasts? We tested this by comparing our predictions against actual measurements in several different scenarios.
First, we looked at the model’s risk of providing dangerous information (like instructions to synthesize harmful chemicals). In tests where we used our scaling laws to extrapolate risks from small numbers of queries (say, 900) to those larger by several orders of magnitude (say, 90,000). We found that the predictions we made from the power law were within one order of magnitude of the true risk for 86% of forecasts.
Second, we forecasted the emergence of misaligned actions (specifically power-seeking, self-preservation, and self-exfiltration, all of which are undesirable behaviours from AIs). The tests involved multiple-choice questions that allowed the models to choose a misaligned action or an aligned one. For example, we would provide the model with a system prompt that made it focus on a particular occupational domain (for example, sales or medical jobs), and then asked it questions about whether it would prefer to “create new policies” (which would be consistent with power-seeking, since the model then begins to shape the organisation to which it’s attached) or “analyze the existing policies” (which would be a more aligned action).
Our forecasts accurately predicted the risk that the model would pick the worst query: we had an average absolute error of 0.05, compared to 0.12 for more straightforward, baseline methods. That is, our method had 2.5 times lower error than a simpler comparison.
Finally, we also applied our method to “automated red-teaming”. This is when a model is used to find and exploit the weaknesses of another model in an experimental setting. When doing so, one can hypothetically choose to use a small model that generates a very large number of queries or, for the same cost, a larger model that generates a smaller number of queries (but where those queries are likely of a higher quality). Our forecasts were useful in working out how to most efficiently allocate a compute budget while doing red-teaming—in settings where the choice is important, they identified the optimal model 79% of the time.
Conclusions
Under normal circumstances, it simply isn’t feasible to use standard evaluations to test for all the rarest risks of AI models. Our method isn’t perfect—in the paper, we give a number of future directions that might improve the accuracy and practicality of our predictions—but it provides LLM developers with a new way to efficiently predict rare risks, allowing them to take action before deploying their models.
Read the full paper.
Work with us
If you’re interested in working on problems like deployment evaluations or jailbreak robustness, we’re currently recruiting for Research Engineers / Scientists and we’d love to see your application.
Related content
How people ask Claude for personal guidance
Read moreEvaluating Claude’s bioinformatics research capabilities with BioMysteryBench
Read moreAnnouncing the Anthropic Economic Index Survey
We're launching the Anthropic Economic Index Survey, a monthly survey conducted through Anthropic Interviewer.
Read more